
本项目实现了一个基于 本地大语言模型(Ollama) 的智能问答后端系统,采用 FastAPI + AsyncClient + StreamingResponse 构建模块化服务框架,支持与本地模型(如 deepseek-r1:7b)进行 流式对话交互。系统已完成前后端联调,并具备良好的 异步处理能力、模型切换拓展性与接口可复用性,为金融 AI 助手平台打下稳固基础。
一、项目目标
构建一个 AI 金融科研助手后端,实现:
- ✉️
/chat接口:支持请求并返回流式文本 - 🤖 接入本地 Ollama 大模型(deepseek-r1:7b)
- 🔄 支持 StreamingResponse 返回方式
- 🛠️ FastAPI 构建模块化后端
二、环境配置 & 项目结构
环境
- 系统:macOS Sonoma 14.5
- 设备:MacBook Pro (M1 Pro, 16GB)
- 系统 Python 管理:
pyenv - 模型服务:Ollama (deepseek-r1:7b)
技术栏
| 组件 | 技术 |
|---|---|
| Web 框架 | FastAPI |
| 大模型 | Ollama (local) |
| HTTP 客户端 | httpx |
| 流式返回 | StreamingResponse + AsyncClient |
| 项目结构 | routers / services / models 分层 |
目录结构
1 | backend/ |
三、打造步骤
1. Python 环境初始化
1 | brew install pyenv |
2. 安装后端依赖
1 | pip install fastapi "uvicorn[standard]" python-multipart httpx |
3. 启动 FastAPI 服务
1 | uvicorn app.main:app --reload |
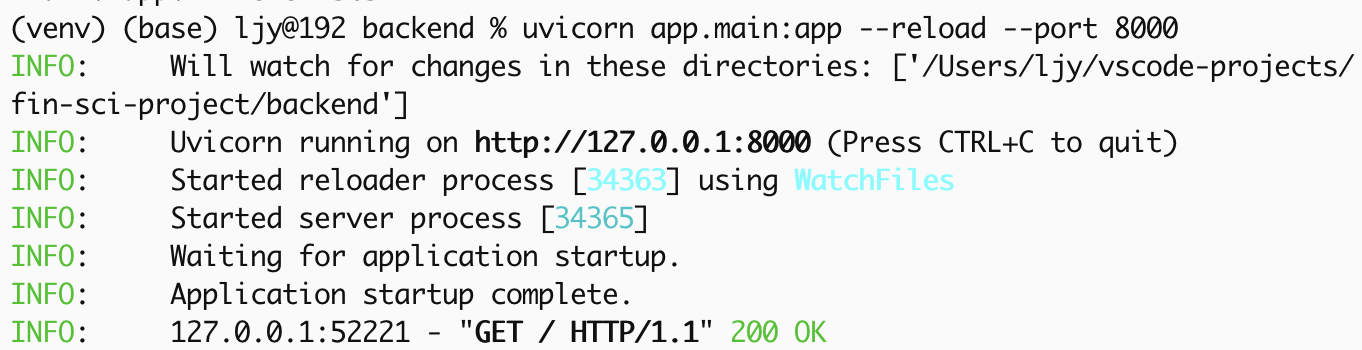
且配置 CORS:
1 | allow_origins = ["http://localhost:3000"] |
4. 安装并启动 Ollama
1 | ollama run deepseek-r1:7b |
测试:
1 | curl http://localhost:11434/api/generate \ |
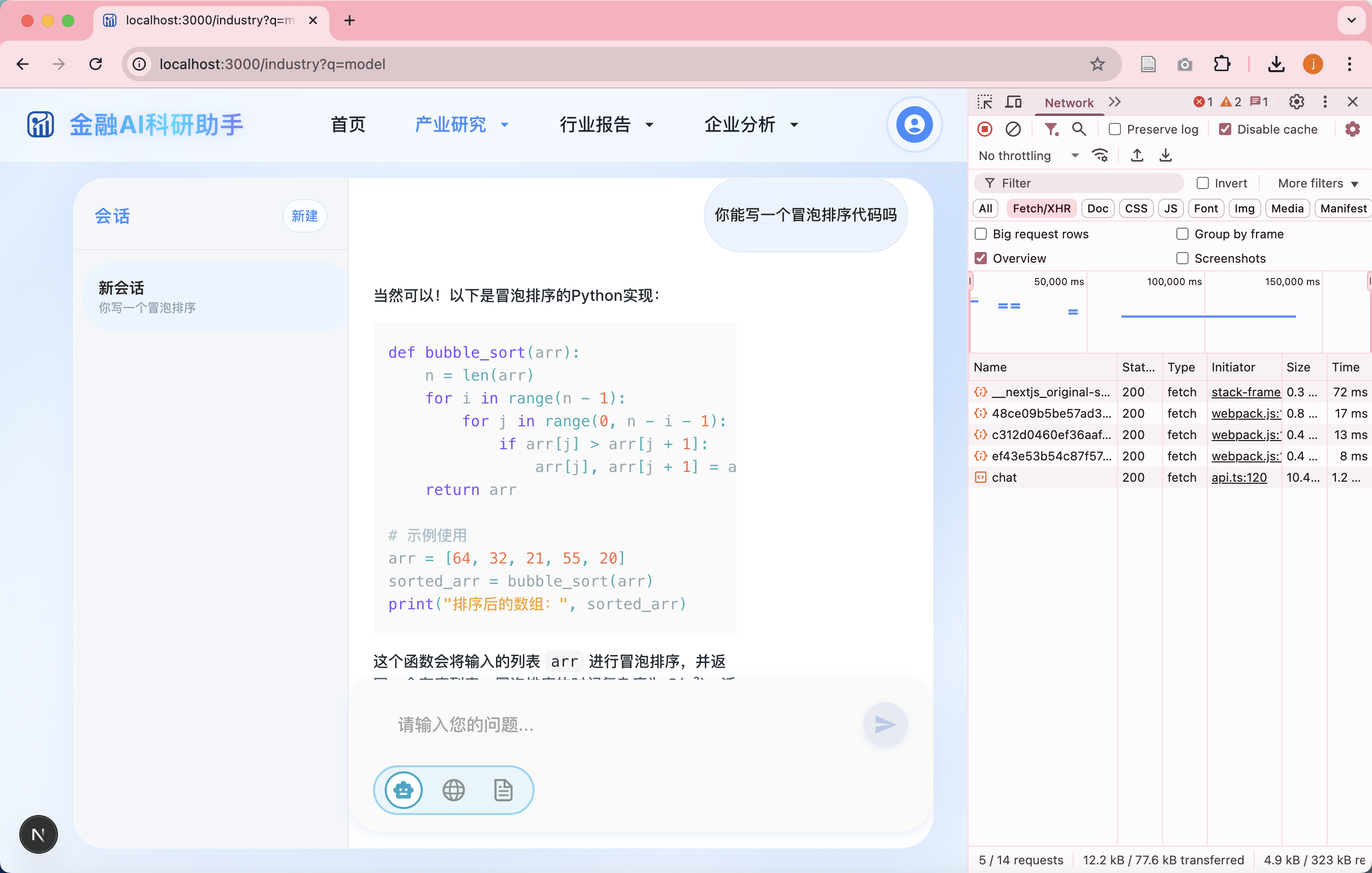
5. /chat 接口实现
- 请求体:
{ "user_input": "..." } - 返回:
StreamingResponse
流程:
- 调用 httpx.AsyncClient.stream() 联通 Ollama
- 请求异步读取每一条 token
- 通过 FastAPI StreamingResponse 返回
四、调试工具
| 工具 | 用途 |
|---|---|
| REST Client | VS Code 内置测试 POST |
| Thunder Client | GUI 测试(Postman 替代) |
| Swagger UI | FastAPI 提供的 /docs 页面 |
五、当前成果
- ✅ FastAPI 后端结构化完成
- ✅ 本地 deepseek-r1:7b 模型接入
- ✅ 实现流式归回 /chat 接口
- ✅ 已完成前后端联调 (Next.js)
—— 本文完 · 感谢读到这里的你 🐾 ——
作者
金金
版权
采用



 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 许可,转载请注明出处。
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 许可,转载请注明出处。