
这篇博客详细介绍了如何在 Mac上从零开始本地部署 LLaMA2大语言模型,结合 Ollama工具实现本地 API 服务,并通过 Next.js前端完成模型调用、结果渲染和接口切换,为乳腺癌预测系统构建了完整的本地智能问答能力,支持后续实现 RAG。
💻 适配环境
- 设备:MacBook Pro 14”(Apple M1 Pro, 16GB RAM)
- 系统:macOS Sonoma 14.5
- 项目:Next.js 14 + 本地大语言模型(LLaMA2 via Ollama)
🧱 步骤总览
| 步骤 | 内容 |
|---|---|
| ① | 安装 Ollama(本地大模型引擎) |
| ② | 下载并测试模型(如 llama2) |
| ③ | 启动 Ollama 本地服务 |
| ④ | 接入 Next.js 项目中 |
| ⑤ | 使用 /api/local-llm 调用模型 |
| ⑥ | 在前端添加问答按钮/切换逻辑 |
🔧 第一步:安装 Ollama
1 | brew install ollama |
启动后台服务:
1 | ollama serve |
开机自启(可选):
1 | brew services start ollama |
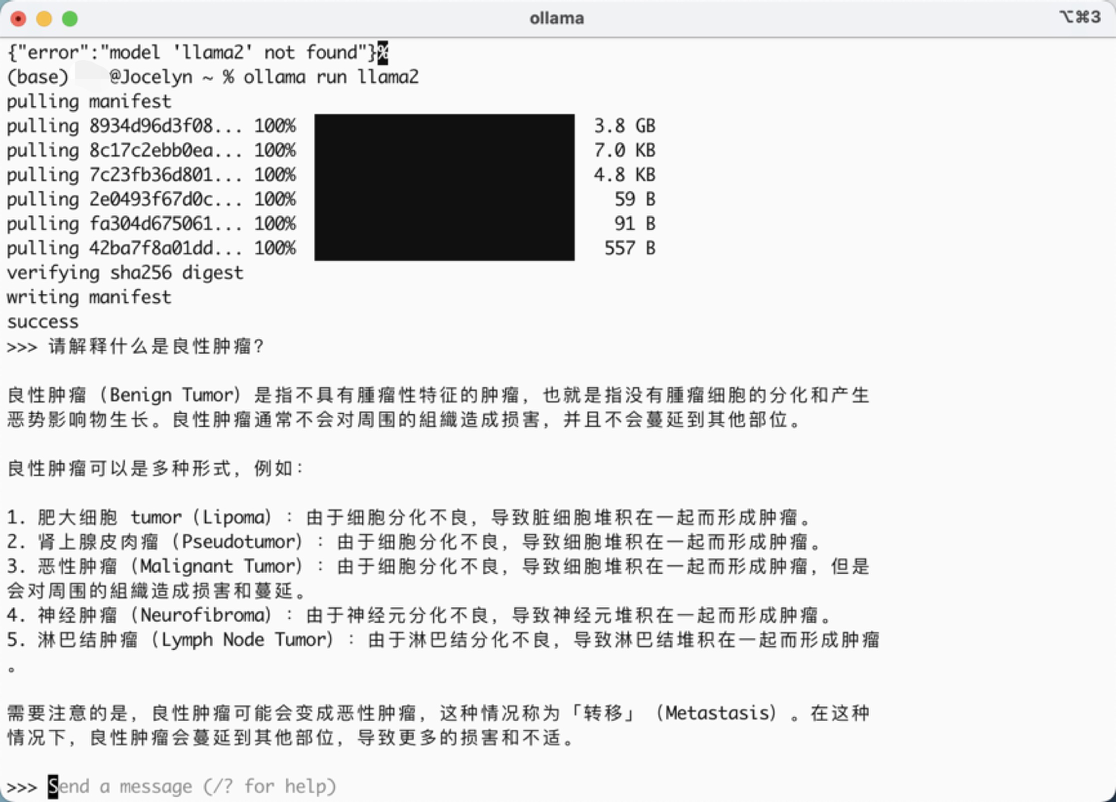
📦 第二步:运行模型
下载并运行 LLaMA2:
1 | ollama run llama2 |
测试本地 API:
1 | curl http://localhost:11434/api/generate -d '{ |
🧠 第三步:创建本地 LLM API 接口
路径:frontend/src/app/api/local-llm/route.ts
1 | export async function POST(req: Request) { |
🔄 第四步:调用流程
1 | 用户点击“AI解析”按钮 |
📨 数据格式
请求:
1 | { "prompt": "请根据以下特征解释预测结果..." } |
响应:
1 | { "content": "这是基于你输入的预测数据的详细解释..." } |
🚨 错误处理建议
| 情况 | 处理方式 |
|---|---|
| 模型未运行 | 返回 500 + 提示“请先运行模型” |
| 网络错误 | 返回 JSON { error: ... } |
| Prompt 缺失 | 返回 400 提示 “缺少输入” |
✅ 安全 & 可维护建议
- 限制请求长度
- 日志记录失败信息
- 默认 prompt 模板统一
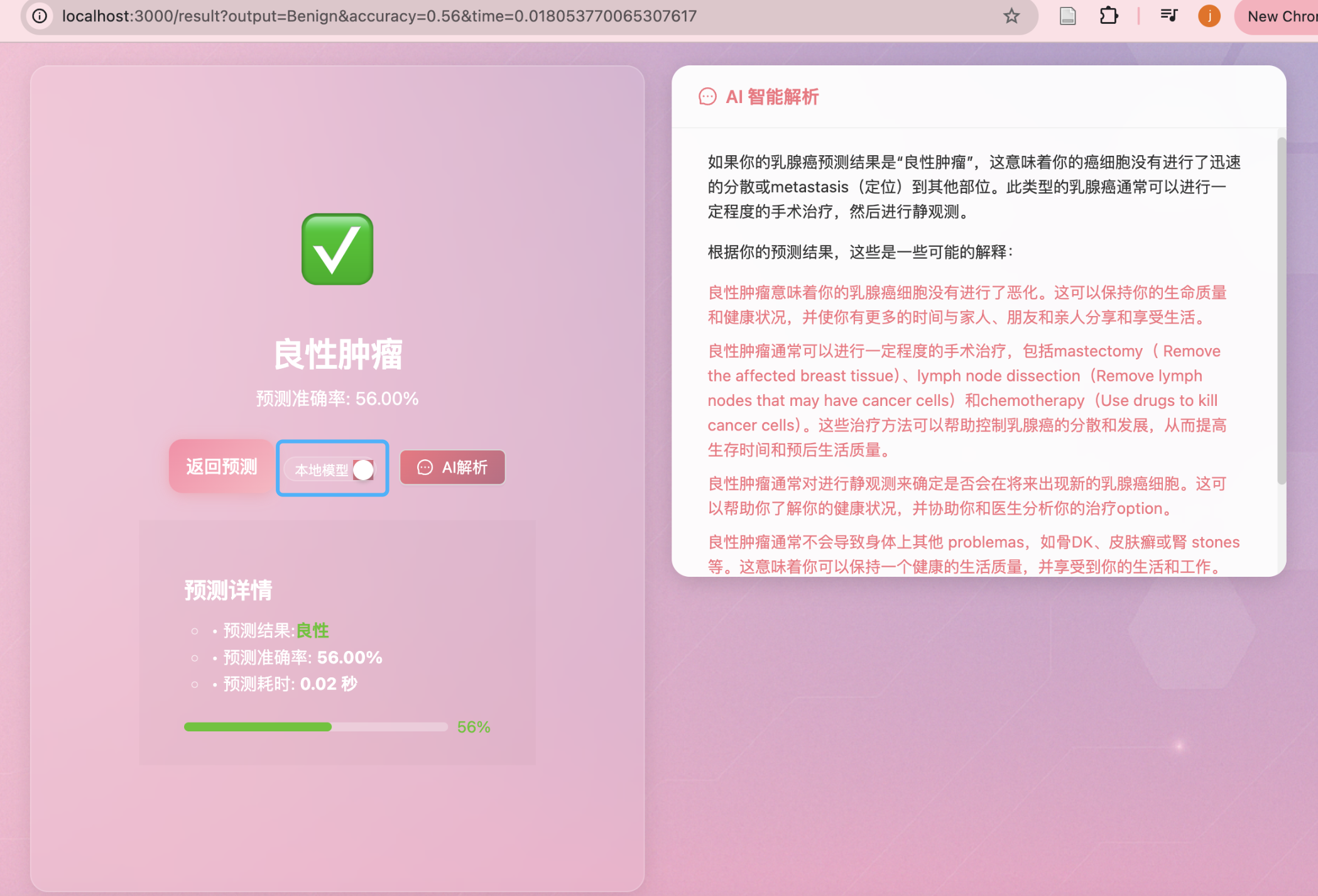
✅ 效果示意
- AI 按钮支持“本地/云端”切换
- 本地模型解释预测结构
- 用户自由提问
- 数据本地运行,0 成本、零泄漏
📌 如需扩展到 RAG(结合报告问答),只需修改 prompt 构造或增加向量检索模块即可。
—— 本文完 · 感谢读到这里的你 🐾 ——
作者
金金
版权
采用



 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 许可,转载请注明出处。
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 许可,转载请注明出处。