
✨ 想踏入分布式计算的世界,却不知道从哪里开始?✨ 本篇博客手把手教你从零搭建 Spark 分布式计算环境!借助 Docker 的力量,将 Spark 和 Hadoop 无缝结合,实现一键部署和高效计算。内容循序渐进,小白友好,还附带常用 Docker 和 Spark 指令教程,助你轻松上手! 🚀
一、在 CentOS 中安装 Docker 🚀
已经下载好docker的可以省略,直接用云服务器内置docker
1.1 停用防火墙和 SELinux
确保 Docker 能正常运行:
1 | systemctl stop firewalld |
1.2 更新 yum 源
将默认 yum 源替换为阿里云镜像源:
1 | yum -y update |
1.3 安装 Docker
1 | yum install -y yum-utils device-mapper-persistent-data lvm2 |
1.4 启动 Docker 并验证
1 | systemctl start docker |
1.5 配置镜像加速器
编辑 /etc/docker/daemon.json 文件,添加阿里云镜像加速器:
1 | { |
重启 Docker:
1 | systemctl daemon-reload |
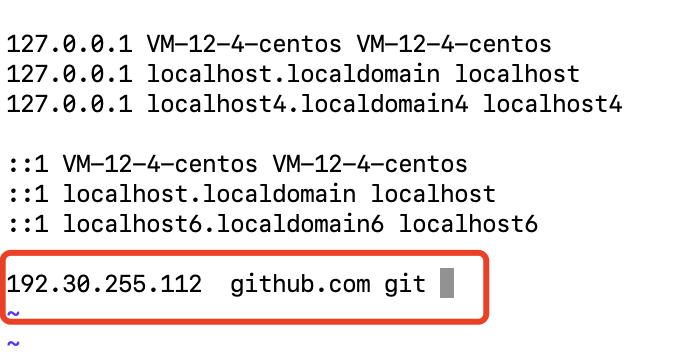
1.6 安装 Git 并配置 hosts
为后续拉取资源安装 Git,并修复访问 GitHub 的 DNS 问题:
1 | yum -y install git |


添加以下内容:
192.30.255.112 github.com git
二、安装 Docker-Compose 🛠️
2.1 安装 Docker-Compose
通过官方方式安装 Docker-Compose:
1 | curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose |

三、使用 Docker 搭建 Spark 环境 🔥
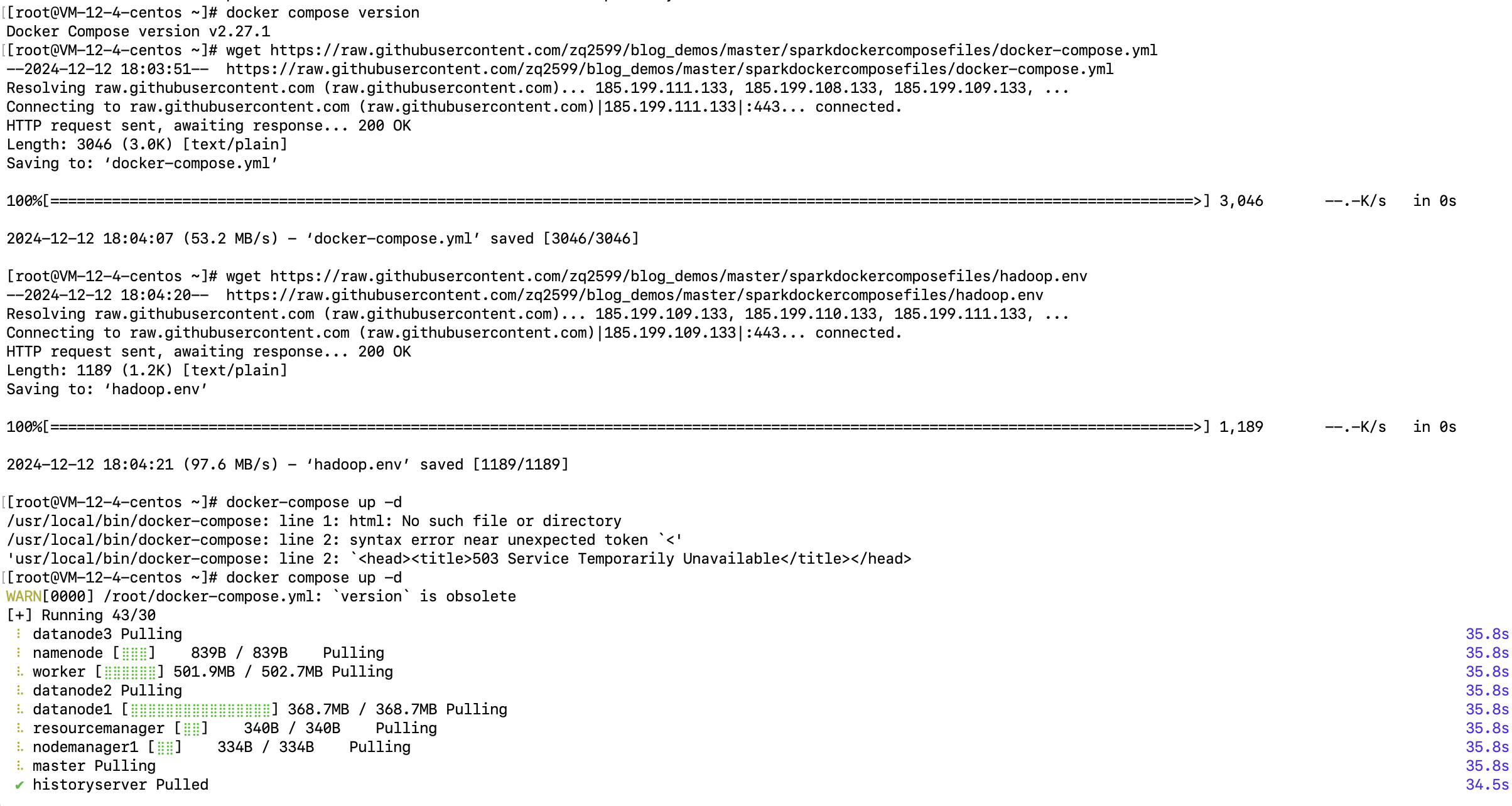
3.1 下载必要文件
1 | wget https://raw.githubusercontent.com/zq2599/blog_demos/master/sparkdockercomposefiles/docker-compose.yml |
3.2 启动容器
运行 Docker-Compose 启动 Spark 集群:
1 | docker-compose up -d |
3.3 验证容器状态
1 | docker ps |

四、验证 Spark 和 Hadoop 环境 🌐
⚠️在云服务器中记得把对应端口的安全组开方,不然浏览器访问不到
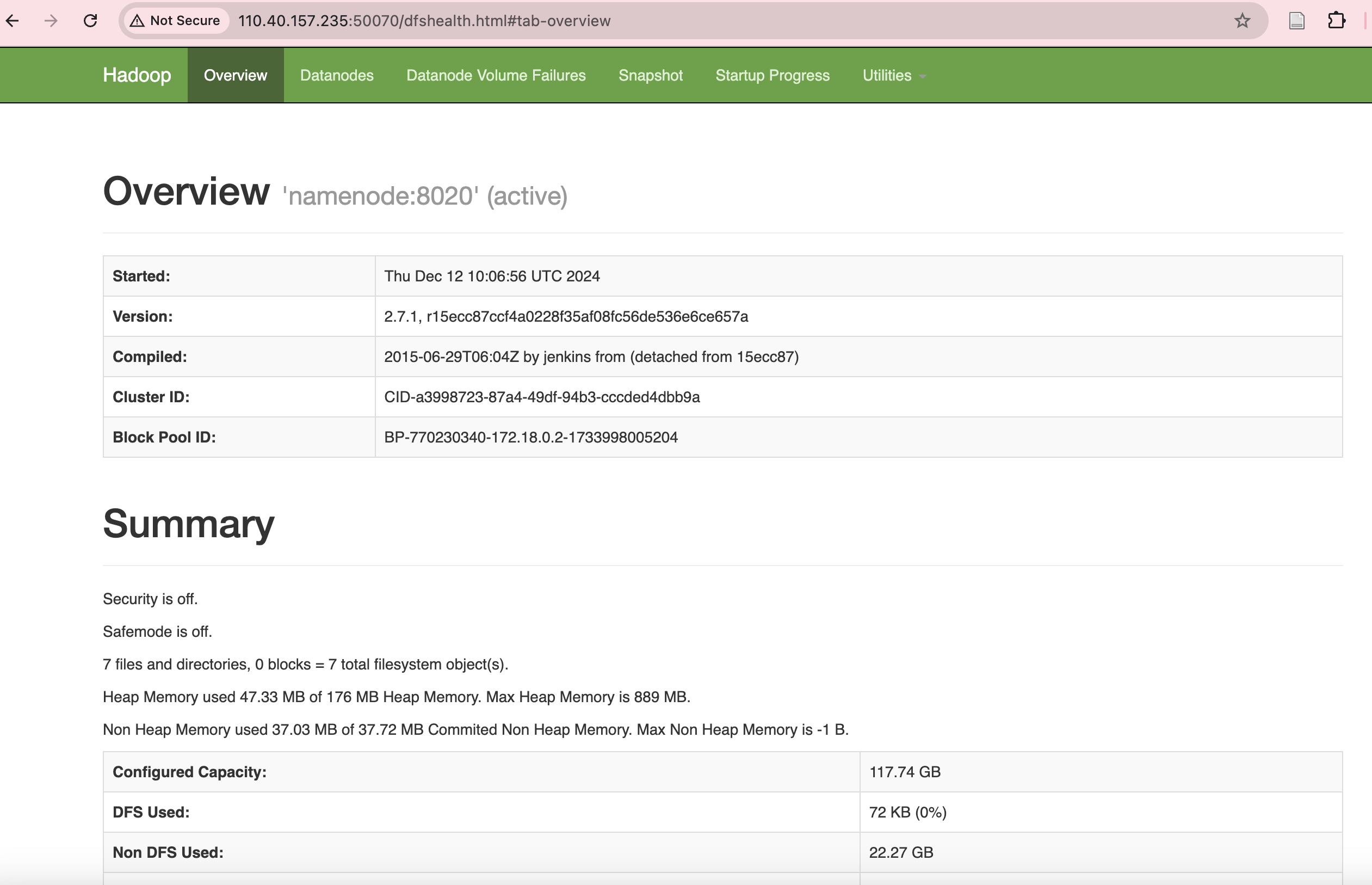
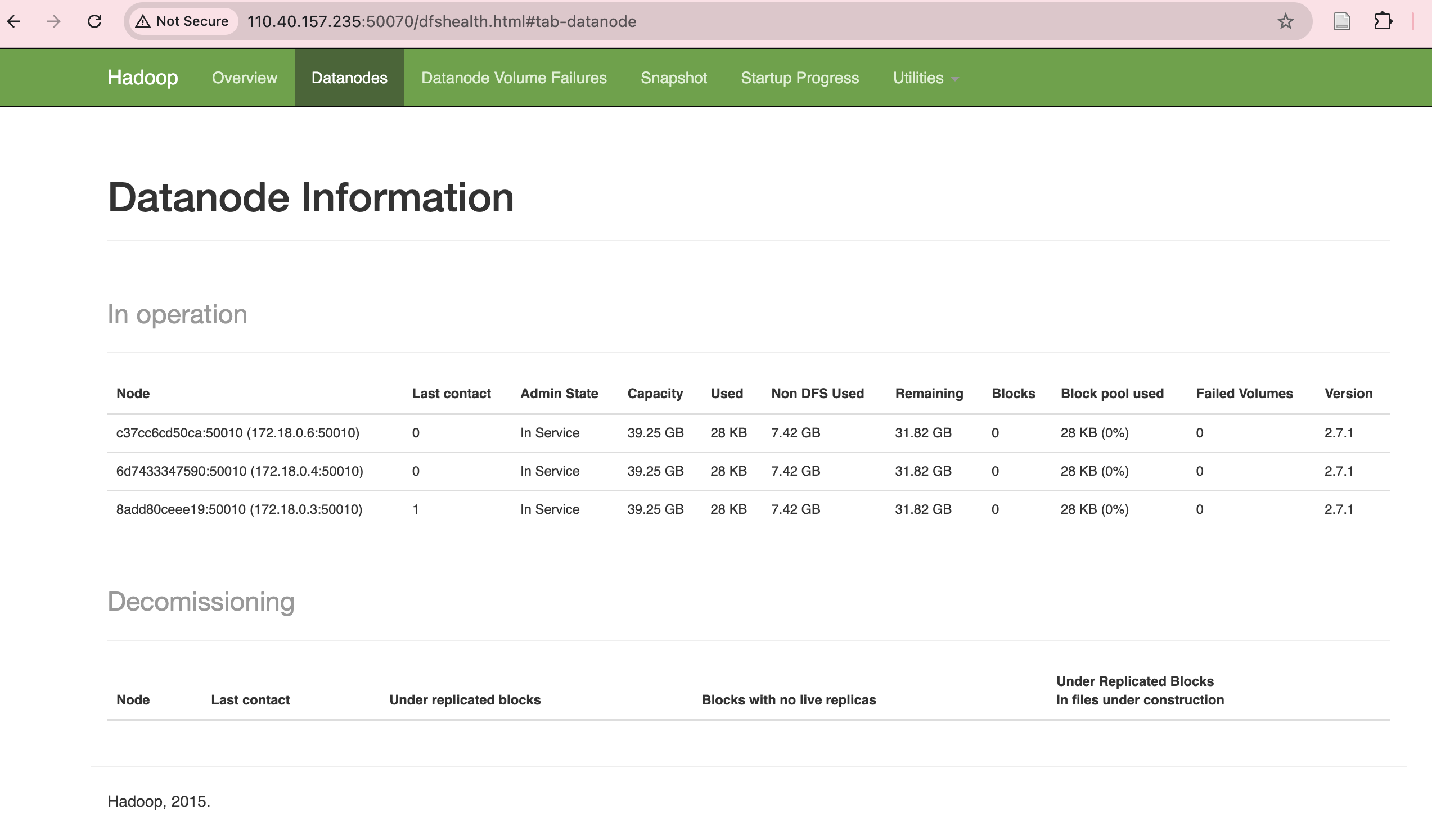
4.1 验证 HDFS
浏览器访问 http://<你的机器IP>:50070/ 查看 HDFS 状态。
4.2 验证 Spark
浏览器访问 http://<你的机器IP>:8080/ 查看 Spark 状态。
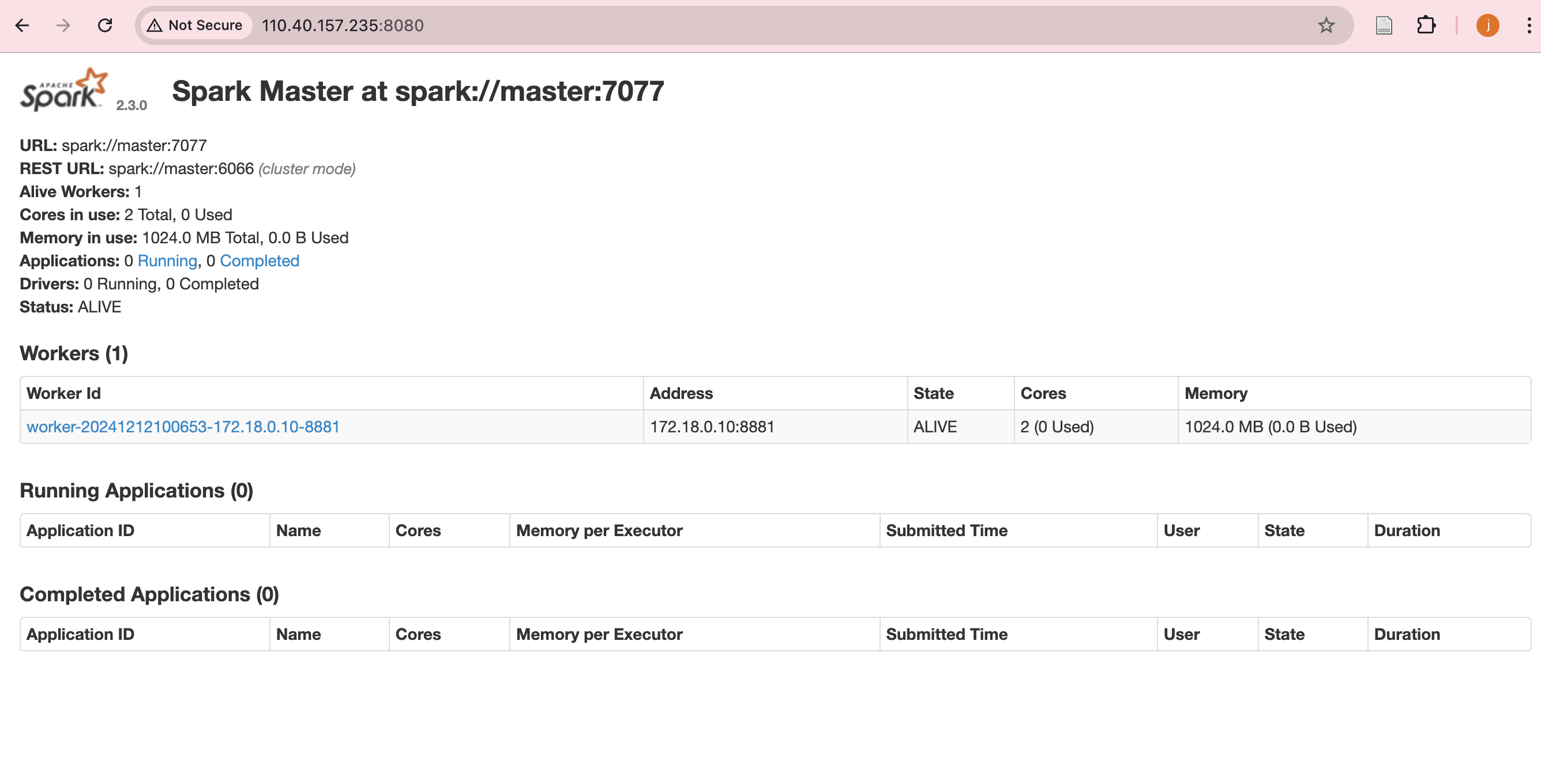
五、运行方式 ✨
使用 spark-shell
通过 Spark 的交互式 shell 运行计算任务:
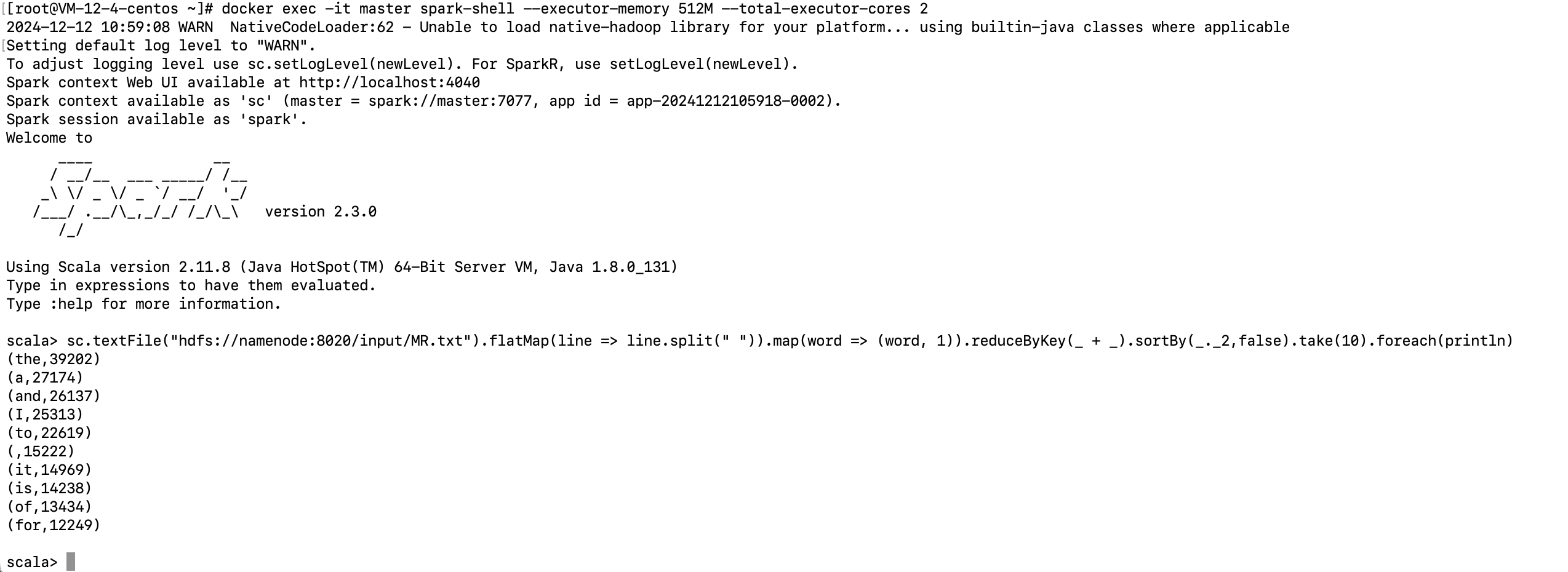
1 | docker exec -it master spark-shell --executor-memory 512M --total-executor-cores 2 |
六、常用 Docker 与 Spark 指令教程 ✨
以下是使用 Docker 和 Spark 进行分布式计算的常用指令和操作说明,帮助你快速上手并高效完成任务。
6.1 创建 HDFS 输入目录
在 HDFS 中创建用于存放输入文件的目录:
1 | docker exec namenode hdfs dfs -mkdir /input |
- 说明:
namenode是 HDFS 的主节点容器名称,/input是新建的目录路径。
6.2 上传文件到 HDFS
将本地文件上传到 HDFS 的 /input 目录:
1 | docker exec namenode hdfs dfs -put /input_files/MR.txt /input |
- 说明:
/input_files/MR.txt是本地路径。/input是目标 HDFS 路径。
6.3 启动 Spark Shell
在 Spark 集群中启动交互式 Spark Shell:
1 | docker exec -it master spark-shell --executor-memory 1G --total-executor-cores 2 --driver-memory 2G |
- 参数说明:
--executor-memory 1G:每个 Executor 分配 1GB 内存。--total-executor-cores 2:总共使用 2 个核心。--driver-memory 2G:Driver 分配 2GB 内存。
6.4 运行 Spark 任务
在 Spark Shell 中执行以下代码,统计文件中出现最频繁的 10 个单词:
1 | sc.textFile("hdfs://namenode:8020/input/MR.txt") |
- 说明:
sc.textFile(...):读取 HDFS 上的文件。.flatMap(...):按空格拆分文件内容为单词。.map(...):为每个单词计数。.reduceByKey(_ + _):统计每个单词的总出现次数。.sortBy(_._2, false):按出现次数降序排序。.take(10):取出前 10 个单词。.foreach(println):打印结果。
6.5 启动 HDFS NameNode
如果 HDFS NameNode 没有启动,可以用以下命令启动:
1 | docker start namenode |
6.6 进入 HDFS 容器
进入 HDFS NameNode 容器的交互式终端:
1 | docker exec -it namenode bash |
- 用途:可以直接在容器内运行 HDFS 命令。
6.7 从 HDFS 合并输出文件
将 HDFS 输出目录中的文件合并为一个文件并保存到本地:
1 | hdfs dfs -getmerge /output/AFR_char.txt /AFR_char.txt |
- 说明:
/output/AFR_char.txt是 HDFS 中的输出目录。/AFR_char.txt是合并后的目标文件名。
6.8 从容器拷贝文件到宿主机
将容器中的文件拷贝到宿主机:
1 | docker cp 8482acf61fef:/AFR_char.txt /root/output/AFR_char.txt |
- 说明:
8482acf61fef是容器 ID(可用docker ps查看)。/AFR_char.txt是容器内的文件路径。/root/output/AFR_char.txt是宿主机上的目标路径。
七、参考资料
—— 本文完 · 感谢读到这里的你 🐾 ——