
摘要:本文以分布式数据处理与任务分解为主题,记录了如何用 Docker 搭建 Spark 集群,实现从零到完成文本文件处理的全过程。🍃 通过四大任务(字符频率统计、单词频率统计、哈夫曼编码表生成、文件压缩编码),文章深入解析代码逻辑与优化技巧✨。全程附带细节讲解与问题排查,图文教程,助力小伙伴轻松搞定大数据初体验!🚀💡
分布式数据处理与任务分解:用 Spark 实现高效文本处理
背景与目标 🎯
在大数据处理任务中,如何有效处理庞大的文本数据是一项关键挑战。本文基于 Docker 搭建 Spark 和 Hadoop 集群,展示了如何实现以下四个核心目标:
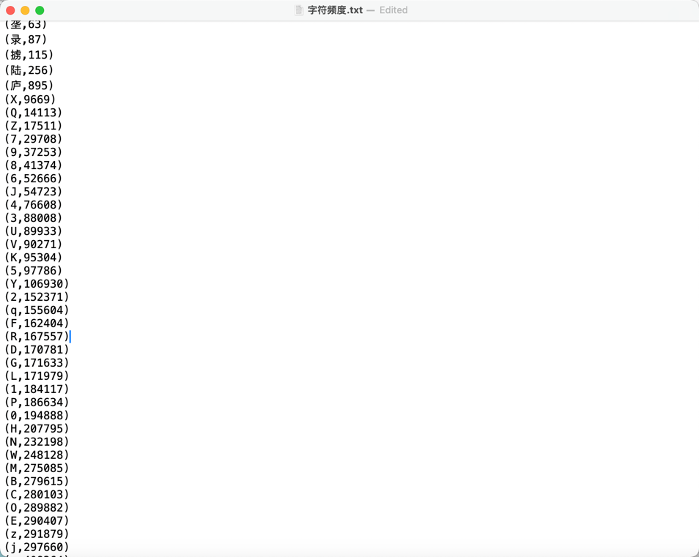
- 统计字符频率:将字符出现的频率按升序输出到
字符频度.txt。 - 统计单词频率:将单词出现的频率按升序输出到
单词频度.txt。 - 生成哈夫曼编码表:为每个字符生成哈夫曼编码并保存为
字符码表.txt。 - 生成文件的哈夫曼编码:基于编码表对整个文件进行压缩并保存为
文件编码.txt。
环境概述 🛠️
- 操作系统:CentOS 7
- 分布式环境:通过 Docker 搭建 Spark 和 Hadoop 集群
- 云服务器配置:2 核 CPU,2GB 内存
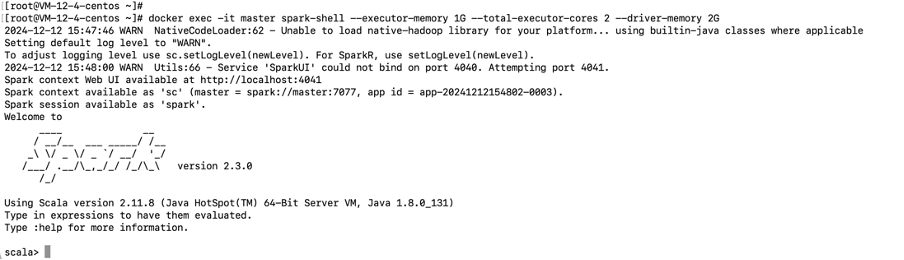
- 处理平台:Spark Shell 和 HDFS 提供分布式存储与计算能力
分布式环境没有的可以参考这篇博文从零开始在 CentOS 上搭建 Spark 环境
将要处理的文件上传到hdfs集群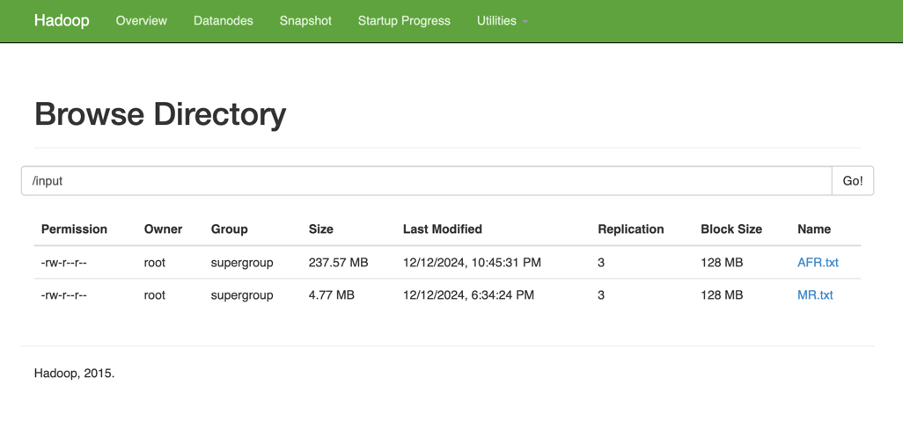
为什么选择 Docker?🤔
在大规模数据处理任务中,Docker 提供了一种轻量化的环境管理方式,具备以下优势:
- 快速部署:开箱即用的 Spark 和 Hadoop 镜像,无需复杂配置。
- 分布式处理:通过多个 Worker 节点模拟真实分布式环境,提升处理效率。
- 灵活资源管理:动态调整容器的 CPU 和内存,优化计算资源。
- 隔离与稳定:容器间互不干扰,确保任务失败时不影响整体运行。
- 高效扩展:支持通过 Docker-Compose 快速调整 Worker 节点数量,满足任务扩展需求。
- 可移植性:配置一次,即可在任意服务器上快速复用。
任务分解与解决方案 📋
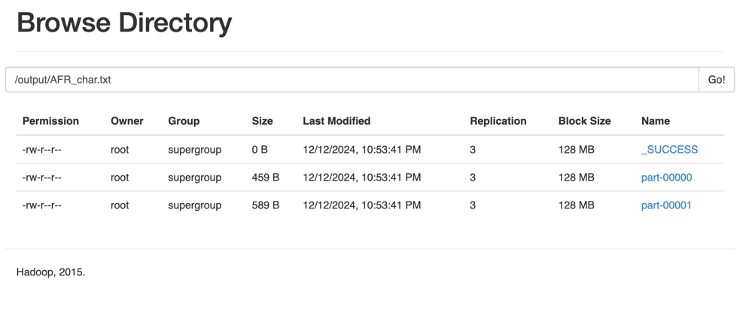
1. 字符频率统计
- 目标:统计文件中每个字符出现的频率,并按升序保存。
- 步骤:
- 加载文本文件为 RDD。
- 拆分为字符并过滤掉非字母和数字的内容。
- 按字符统计频率,按频率升序排序。
- 保存结果到 HDFS。
1 | val rdd = sc.textFile("hdfs://namenode:8020/input/AFR.txt") |
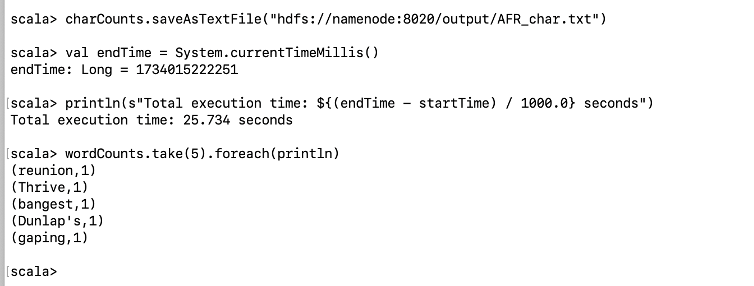
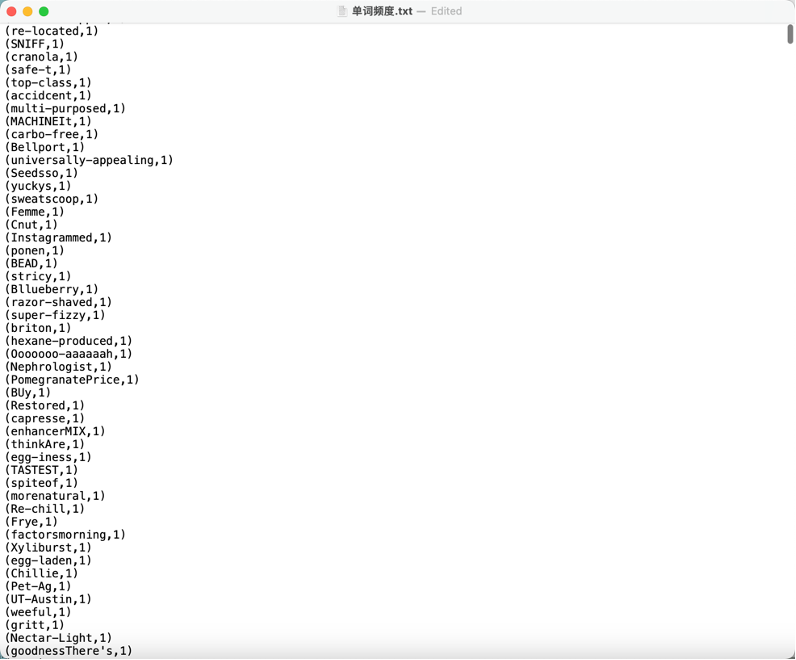
2. 单词频率统计
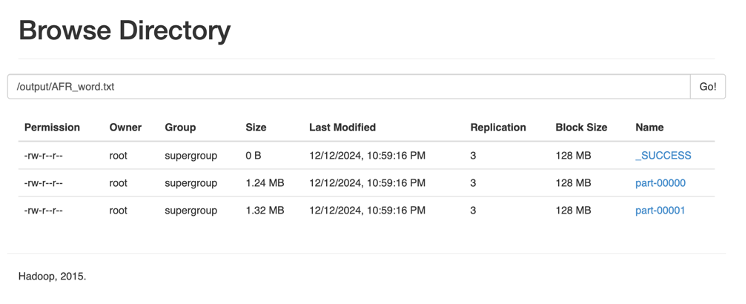
- 目标:统计文件中每个单词的出现频率并升序输出。
- 步骤:
- 移除 HTML 标签,保留纯文本。
- 按空格拆分为单词,过滤无效内容。
- 统计单词频率并排序。
- 保存结果到 HDFS。
1 | val wordCounts = sc.textFile("hdfs://namenode:8020/input/MR.txt") |

3. 哈夫曼编码表生成
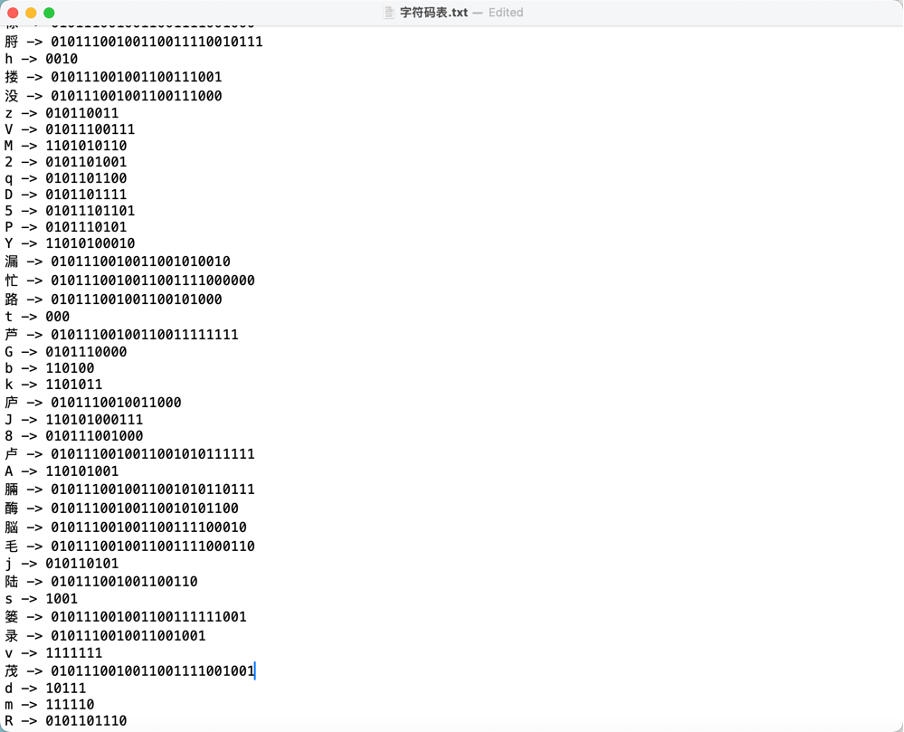
- 目标:为每个字符生成哈夫曼编码表。
- 步骤:
- 统计字符频率,构建哈夫曼树。
- 递归生成每个字符的编码。
- 保存编码表到 HDFS。
1 | import scala.collection.mutable.PriorityQueue |
4. 文件哈夫曼编码
- 目标:根据编码表,对整个文件进行压缩。
- 步骤:
- 替换文件中每个字符为对应的哈夫曼编码。
- 保存编码后的文件到 HDFS。
1 | val encodedFileRdd = rdd.map(line => line.flatMap(char => huffmanCodes.getOrElse(char, ""))) |
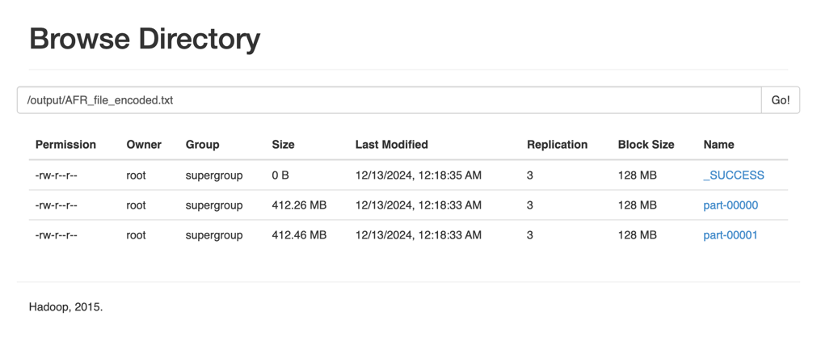
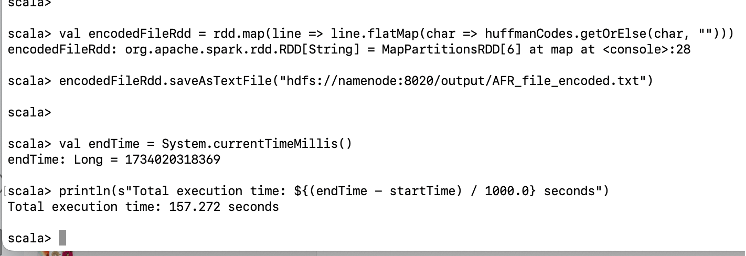

使用方法与优化建议 🔧
- 分布式优势:借助 Spark 的分布式能力,高效处理大规模数据。
- 灵活扩展:通过 Docker 动态调整 Worker 数量,应对不同数据规模。
- 代码优化:利用 Spark 提供的 RDD API,简化复杂计算逻辑。
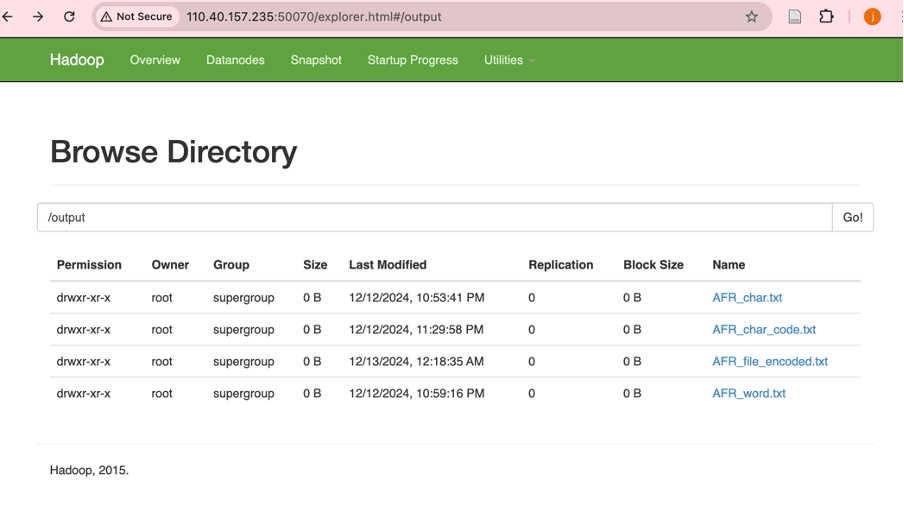
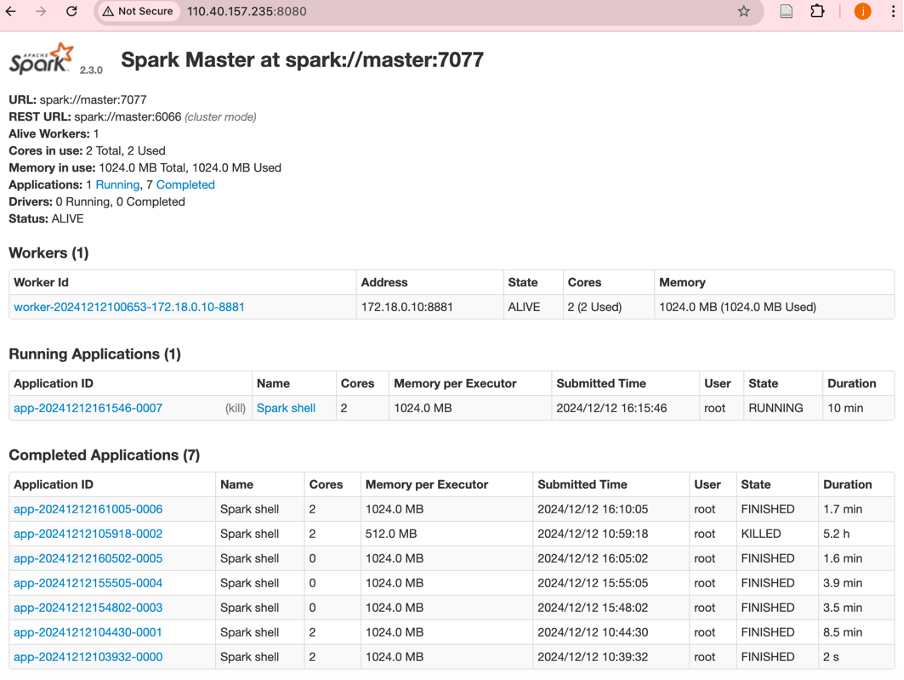
总结 🏁
通过 Docker 部署的 Spark 和 Hadoop 环境,我们高效完成了文本文件的字符统计、单词统计和压缩编码任务。这一方法适用于大规模数据处理,具有良好的扩展性和稳定性。未来可以进一步优化资源配置,提高处理性能。
—— 本文完 · 感谢读到这里的你 🐾 ——
作者
金金
版权
采用



 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 许可,转载请注明出处。
知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 许可,转载请注明出处。