
本文是一份针对初学者的 大数据分析流程与常用技术 笔记,涵盖了大数据分析流程的数据 采集、存储与管理、计算、应用,以及常用的数据 采集、预处理、存储与管理、分析处理、挖掘、可视化 技术。笔记源自大数据学习实践课(中级),其中的配图来自课程 PPT 或听课时自制的思维导图。
大数据分析流程
一、数据采集
○ 实时数据采集
■ Flume、Fluented、Splunk、DataHub
○ 离线数据采集
■ ETL、Sqoop、DataX
二、数据存储
○ 数据存储
■ 关系数据库、mpp数据库、NoSQL数据库、分布式文件系统
○ 数据仓库建模
○ 元数据管理
○ 数据质量控制
○ 数据安全管理
三、数据计算
○ 多维统计分析
○ 大规模并行计算框架
○ 数据挖掘、机器学习模型与算法
○ 分布式实时计算
○ 交互式分析
四、数据应用
○ 数据报表
○ 可视化展现
○ 数据服务
○ 数据分享
云计算:实时、离线
常用技术
一、数据采集技术
1.大数据采集的方法
WEB端
● 基于浏览器:页面浏览日志(pv/uv)、页面交互日志(转化率)
● 网络爬虫/APIAPP端
● 无线客户端:页面浏览事件、控制点击事件
● 采集SDK/埋点传感器
● 物联网:人工智能驾驶:温湿度、障碍物
● 测量值转化数字信号数据库
● 源业务系统:结构化数据 客户、交易等
● 数据同步第三方
● 第三方数据:政府公布宏观数据、对接公安系统等身份核验
● 合作方提供
2.离线数据采集ETL
- 离线数据采集ETL
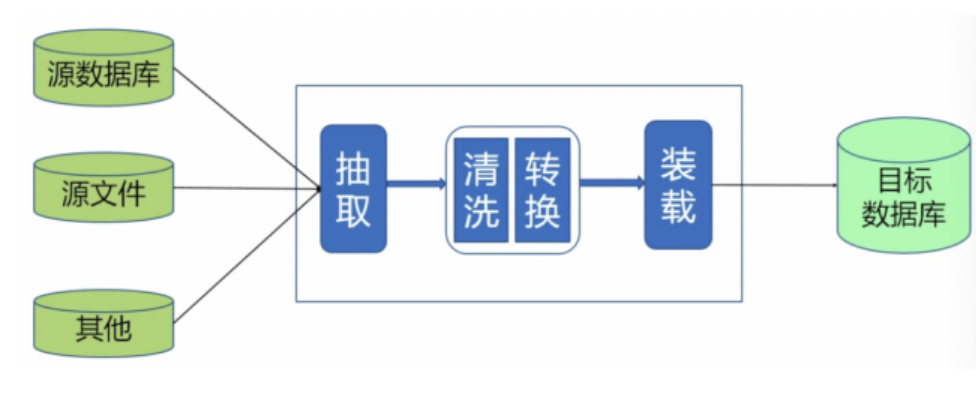
ETL
● Extract:抽取
● Transform:转换
● Loading:装载
3.ETL工具
目前市场上主流的ETL工具有:
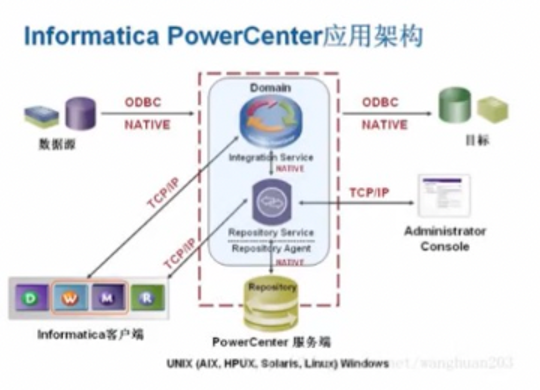
Informatic PowerCenter
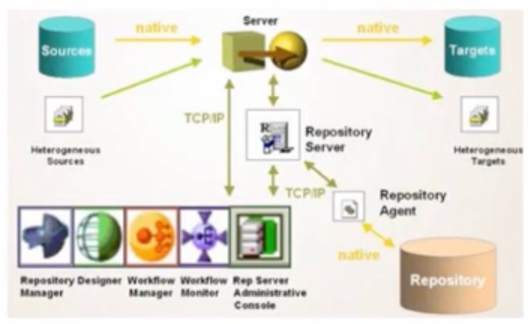
IBM DataStage
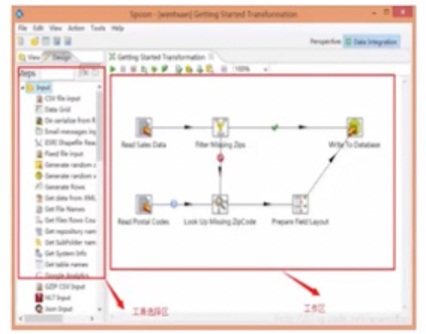
开源Kettle
阿里云DataX
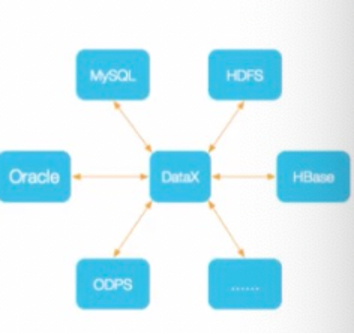
4.实时数据采集与处理
- 消息缓存与传输
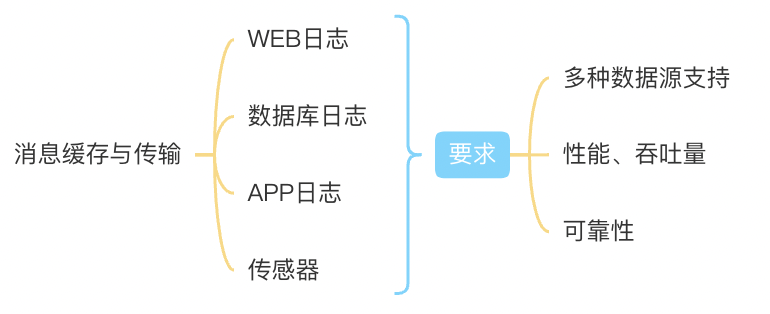
- 实时计算引擎
- 数据存储与应用
工具:
○ Flume
○ Kafka
○ DataHub
5.数据集成
- 定义
针对来自不同数据源的数据,进行合并并整理,形成统一的数据视图 - 需要考虑的问题

- 顺序
1.确定核心信息、可靠关系,完成初步合并
2.寻找拓展关系、融入相关信息、完成二次合并
3.关系发散传递、融入更多信息、完成迭代合并
二、数据预处理技术
1.数据清洗
定义
● 针对原始数据,对出现的噪声进行修复、平滑或者剔除
(包括异常值、缺失值、重复记录、错误记录等)
● 同时过滤掉不用等数据,包括某些行或某些列噪声数据处理
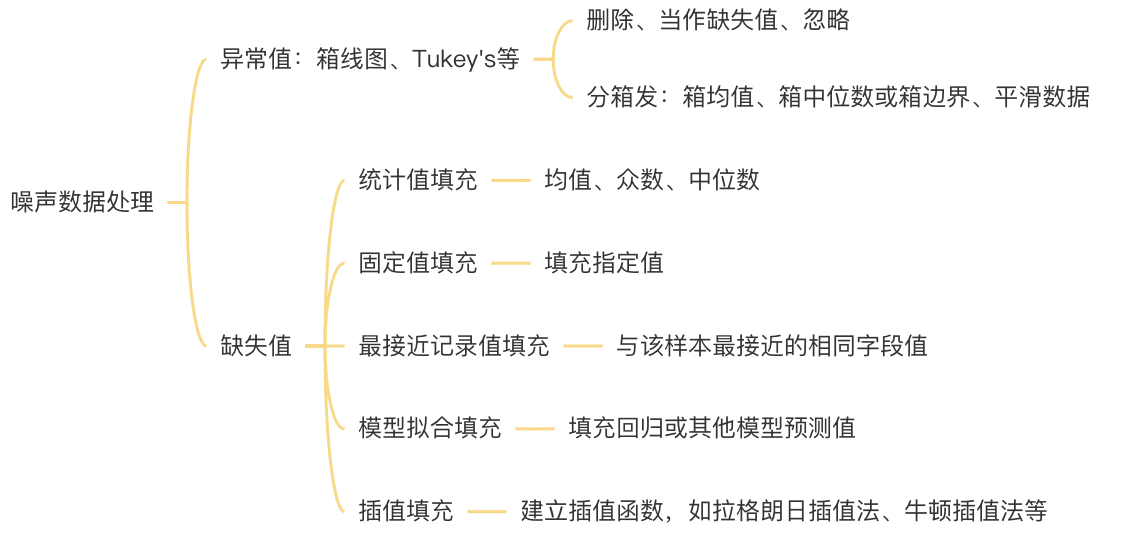
2.数据变换
- 定义
对数据进行变换处理,使数据更合适当前任务或算法的需要 - 常见的变换方式
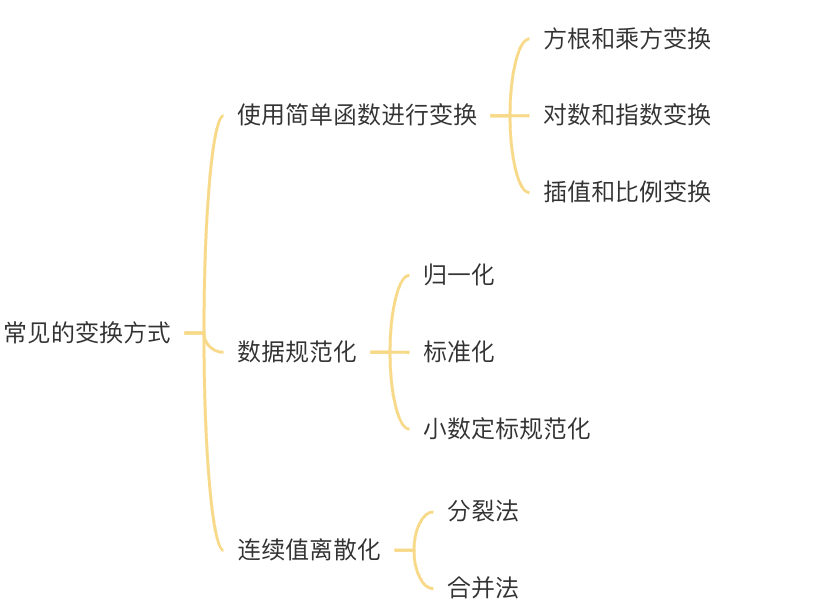
3.数据规约
数据变化
● 在尽可能保持数据原貌的前提下:最大限度第精简数据量
● 主要包括:属性选择、数据抽样数据抽样

三、数据存储与管理
1.结构化数据
行存储:MySQL、Oracle
2.半结构化数据
3.非结构化数据
■ Mongo DB
■ Neo4J
■ OSS
4.分布式文件系统HDFS
介绍
1.Hadoop是一个分布式系统基础架构,由Apache基金开发。
2.用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储。
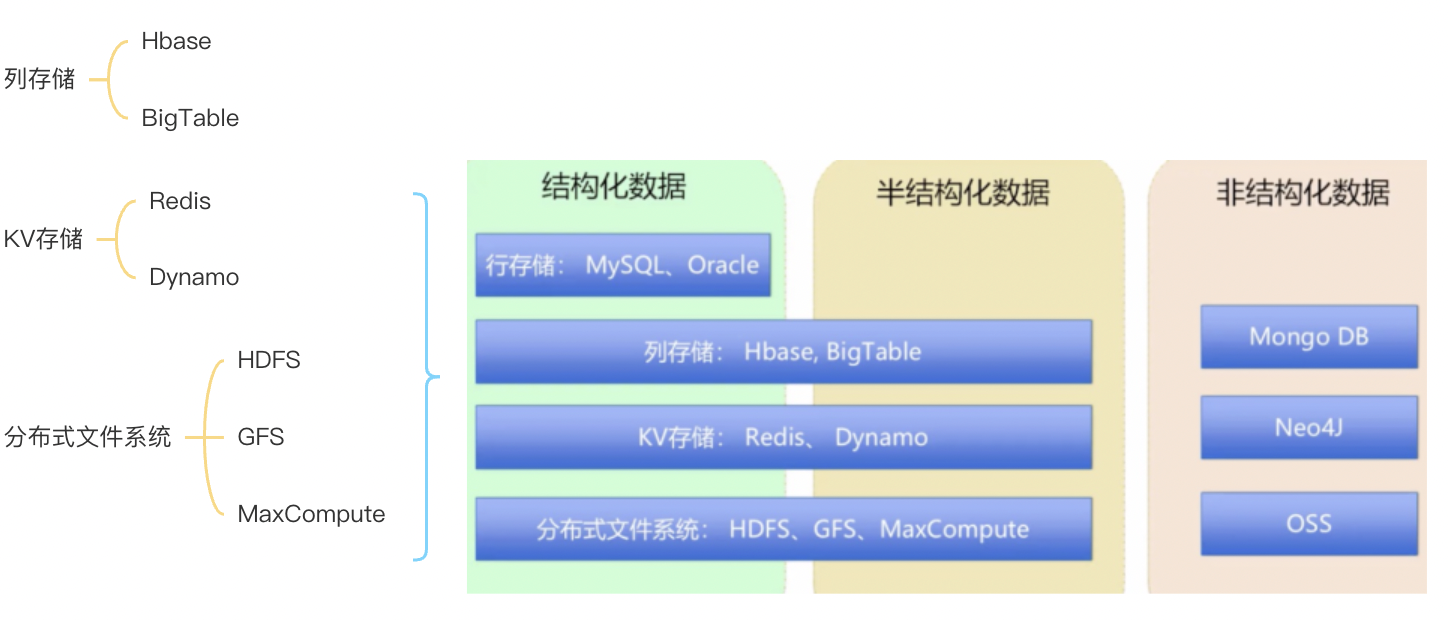
3.Hadoop实现了一个分布式文件系统(Hadoop Distributed File System)简称HDFS特点
HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上HDFS集群
● 一个主节点(NameNode)
● 多个从属节点(DataNodes)
● 多个客户端访问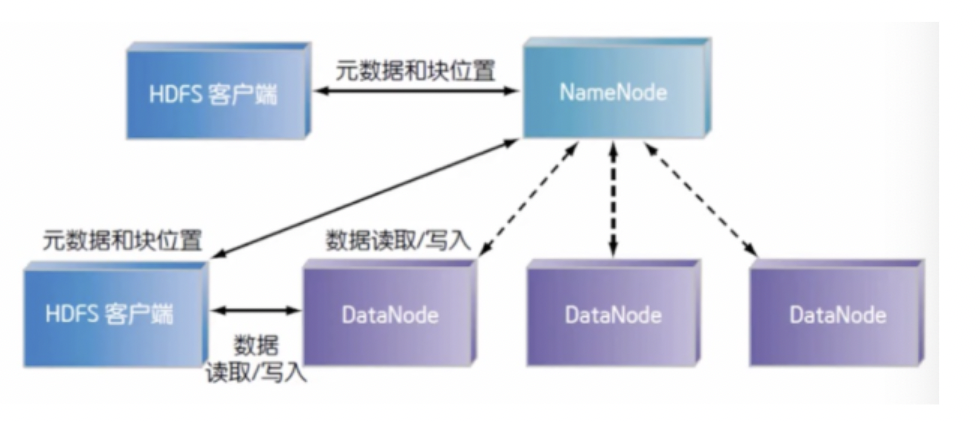
5.分布式列存数据库
介绍
● HBase是一个构建在HDFS上的分布式列存储系统,用于海量结构化、半结构化数据存储。
● HBase的目标是处理非常庞大的表,超过10亿行、数百万列特点
● 高可靠、高性能
● 水平拓展、可伸缩
● 面向列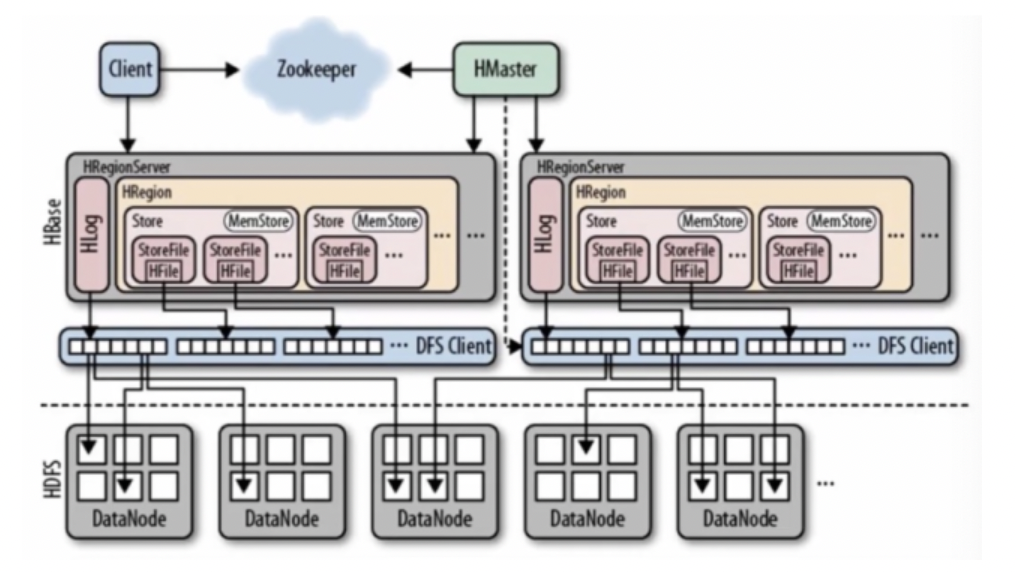
6.内存数据库Redis
- 介绍
● Redis是一个开源的可基于内存亦可持久化的日志型、Key-Value内存数据库
● 也可作为消息的发布、订阅 - 特点
● 高性能、高可用
● 丰富数据类型
● 支持事务
● 丰富客户端、多种语言API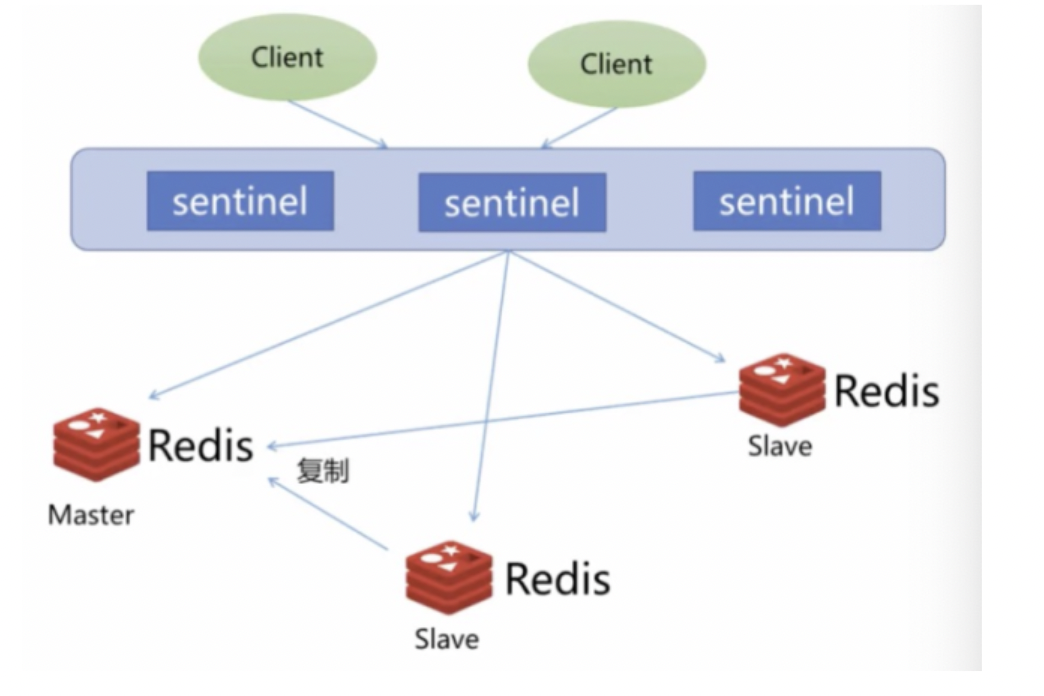
7.消息分发和存储Kafka
- 介绍
● Kafka是分布式发布-订阅消息系统,是可划分的、多订阅者、冗余备份、持久性的日志服务
● 主要用于处理流式数据 - 特点
● 高吞吐量
● 分布式、易拓展
● 支持在线、离线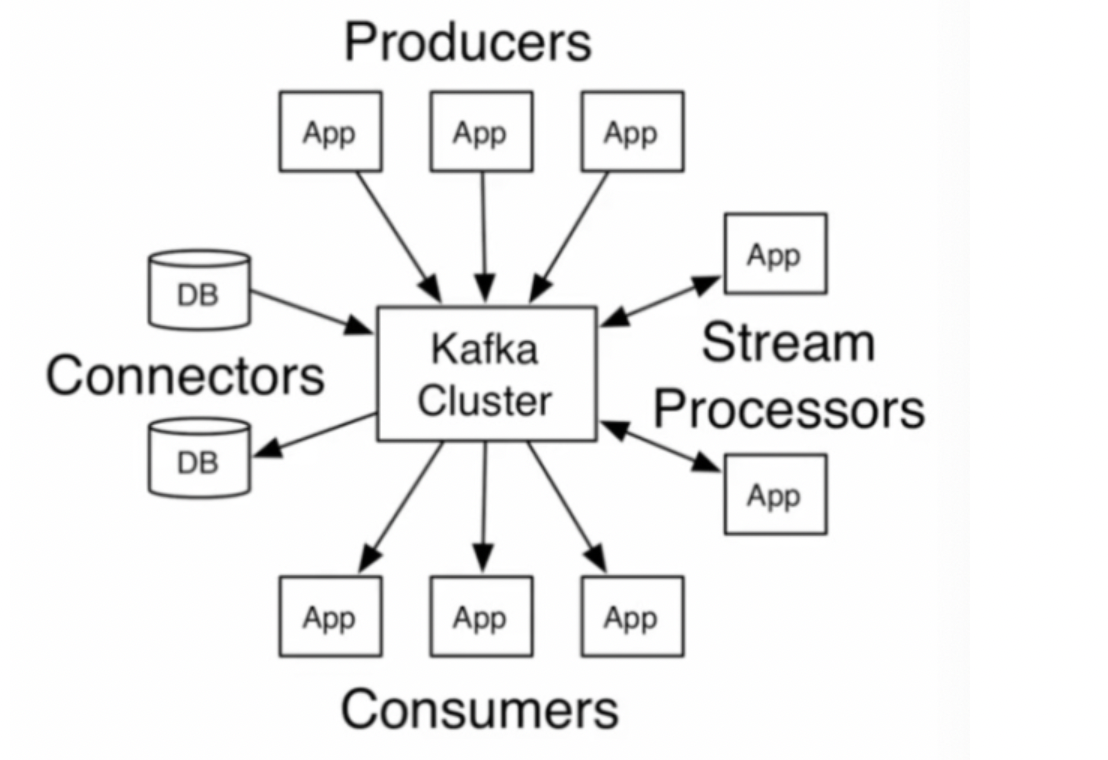
8.非结构化数据存储OSS
- 介绍
● 阿里云对象存储服务(Object Storage Service,OSS)是一种海量、安全、低成本、高可靠的云存储服务,适合存放任意类型的文件
● 容量和处理能力弹性拓展,多种存储类型供选择,全面优化存储成本 - 特点
● 高可靠性
● 安全
● 低成本
● 丰富、强大的增值服务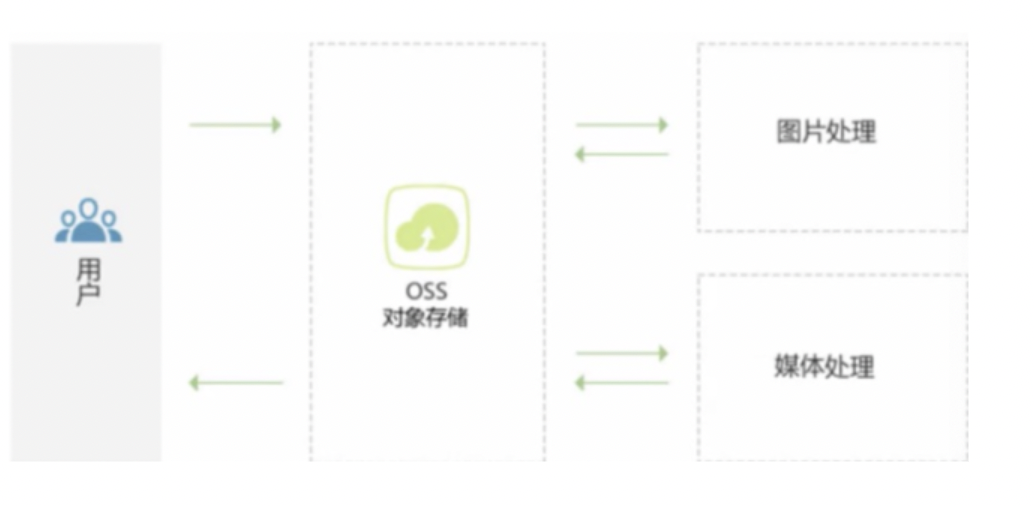
四、数据分析处理技术
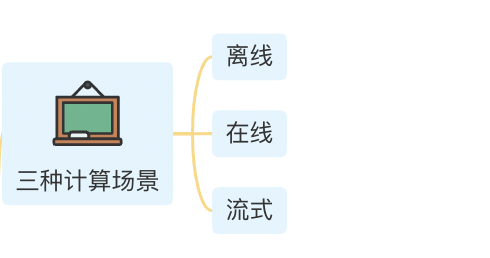
1.三种计算场景
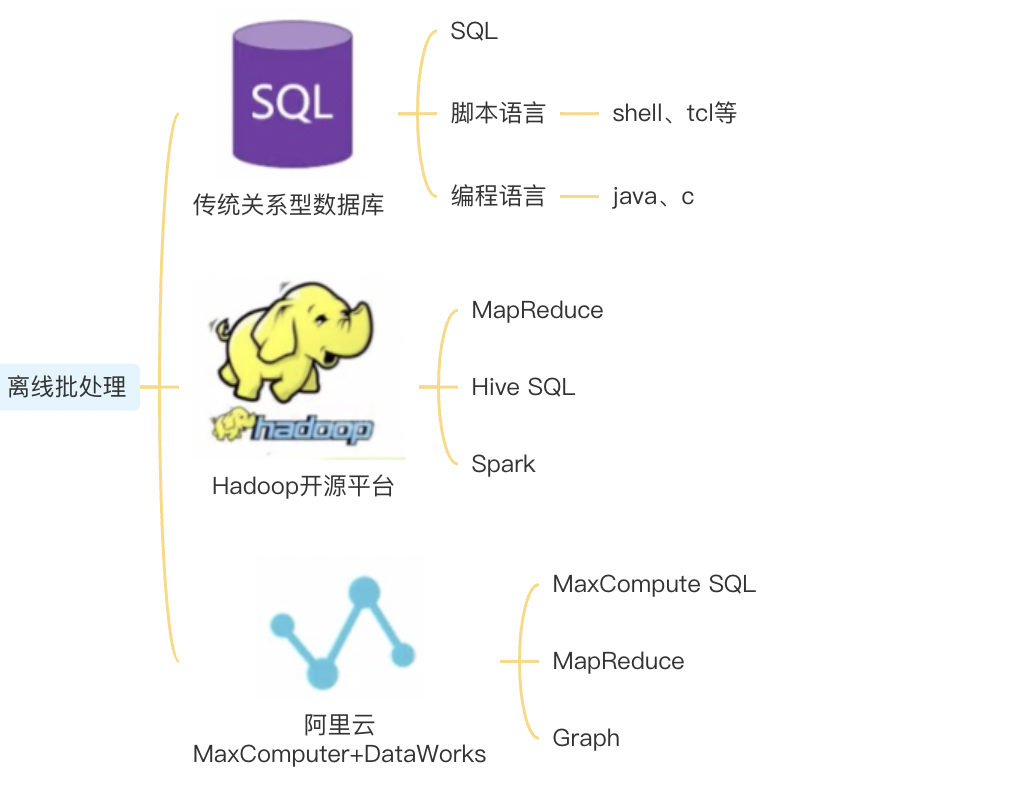
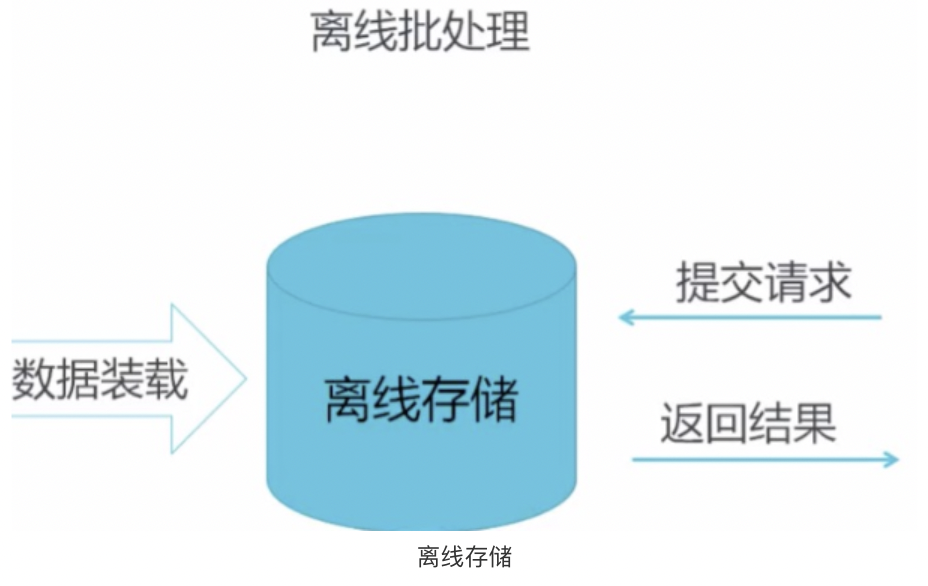
2.离线批处理
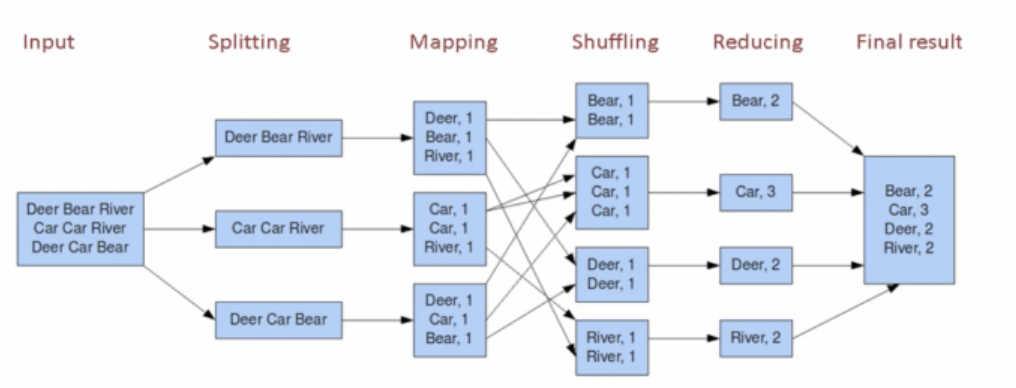
3.分布式离线计算框架MapReduce
■ Input
■ Splitting
■ Mapping
■ Shuffling
■ Reducing
■ Final result
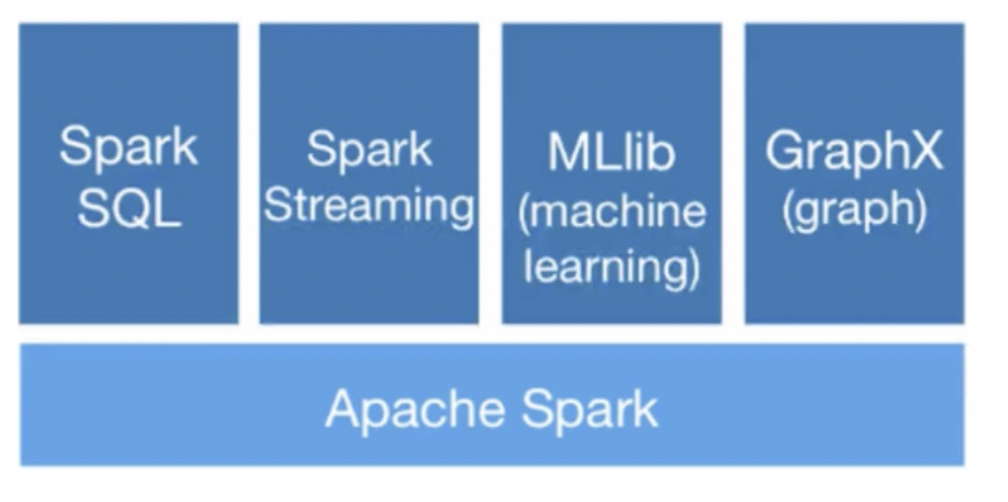
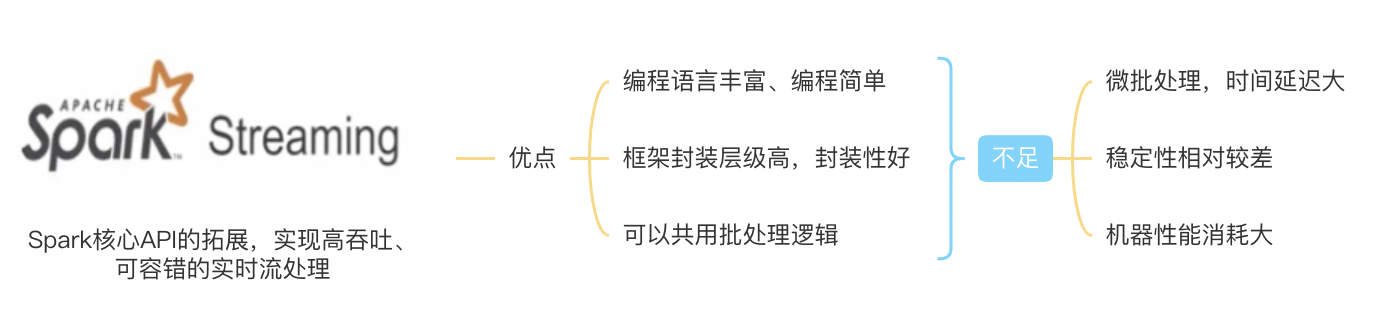
4.通用计算框架Spark
- 介绍
● Spark是一种分布式、通用大数据计算框架
● 可用于离线计算、交互式查询、流式计算、机器学习等 - 特点

5.实时流处理
- 数据装载
- 实时数据流
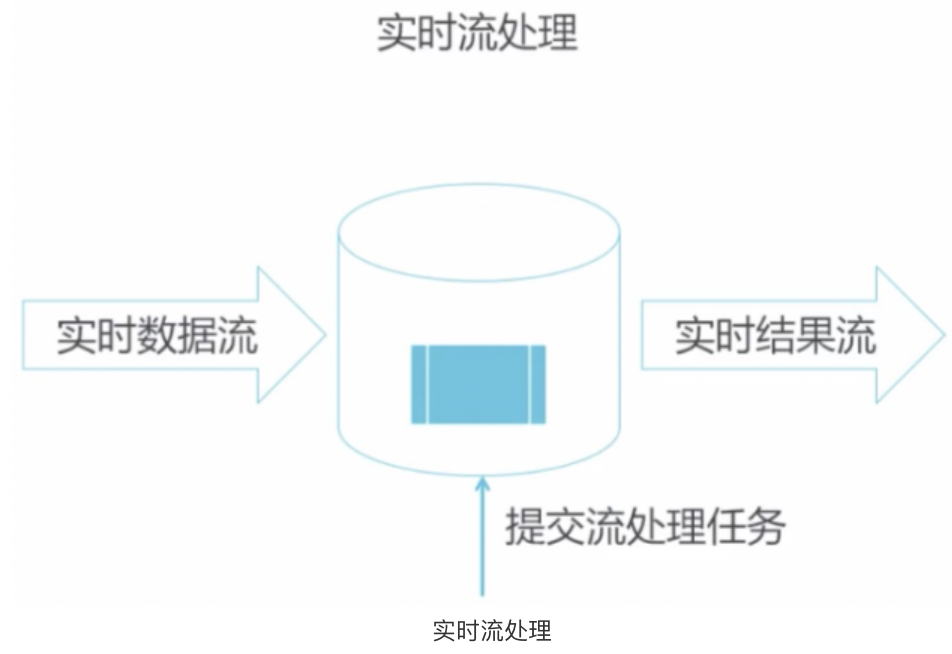
- 实时结果流
6.实时流处理框架平台
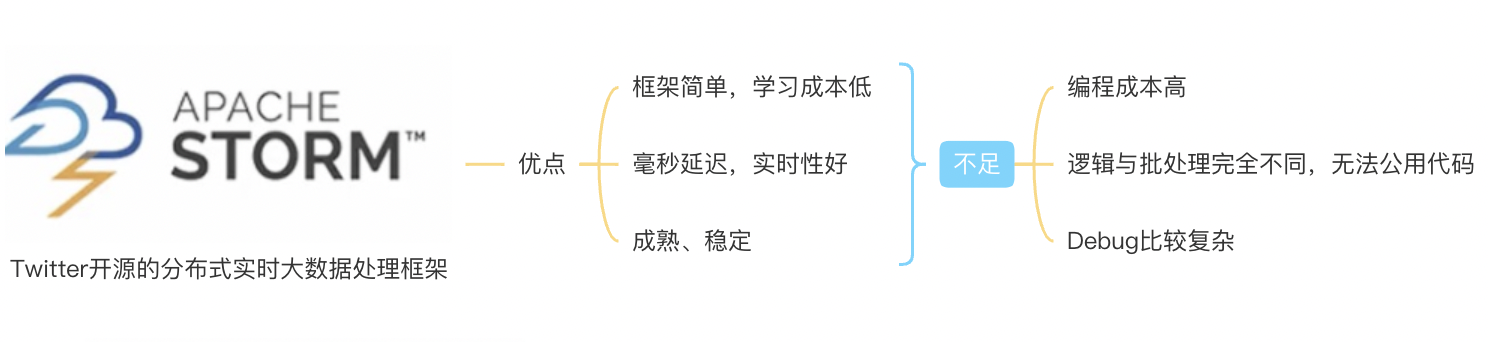
- STROM
- Spark
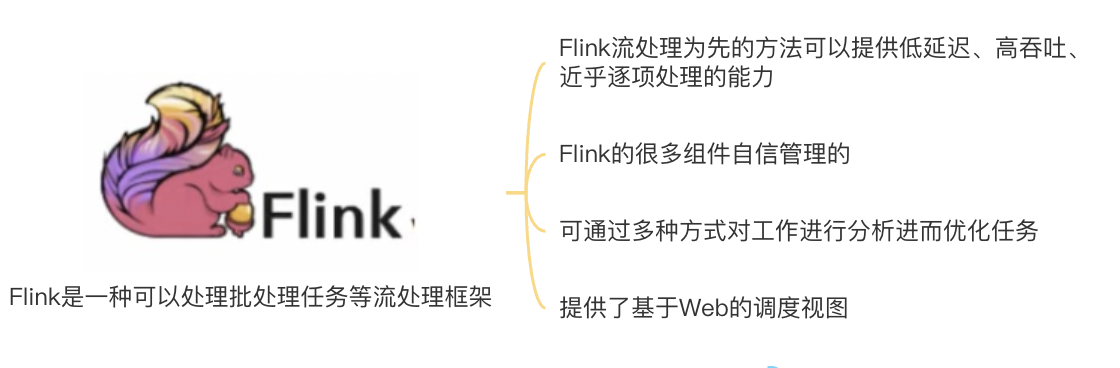
- Flink
7.大数据分析方法
描述型分析
● 发生了什么
● 特点:广泛的,精确的实时数据、有效的可视化诊断型分析
● 为什么会发生
● 特点:能够钻取数据的核心、能够对混乱的信息进行分类预测型分析
● 可能会发生什么
● 特点:使用算法确保历史模型能够用户预测特定的结构、使用算法和技术确保自动生成决定指令型分析
● 下步怎么做
● 特点:依据测试结果来选定最佳的行为和策略、应用先进的分析技术帮助做出决策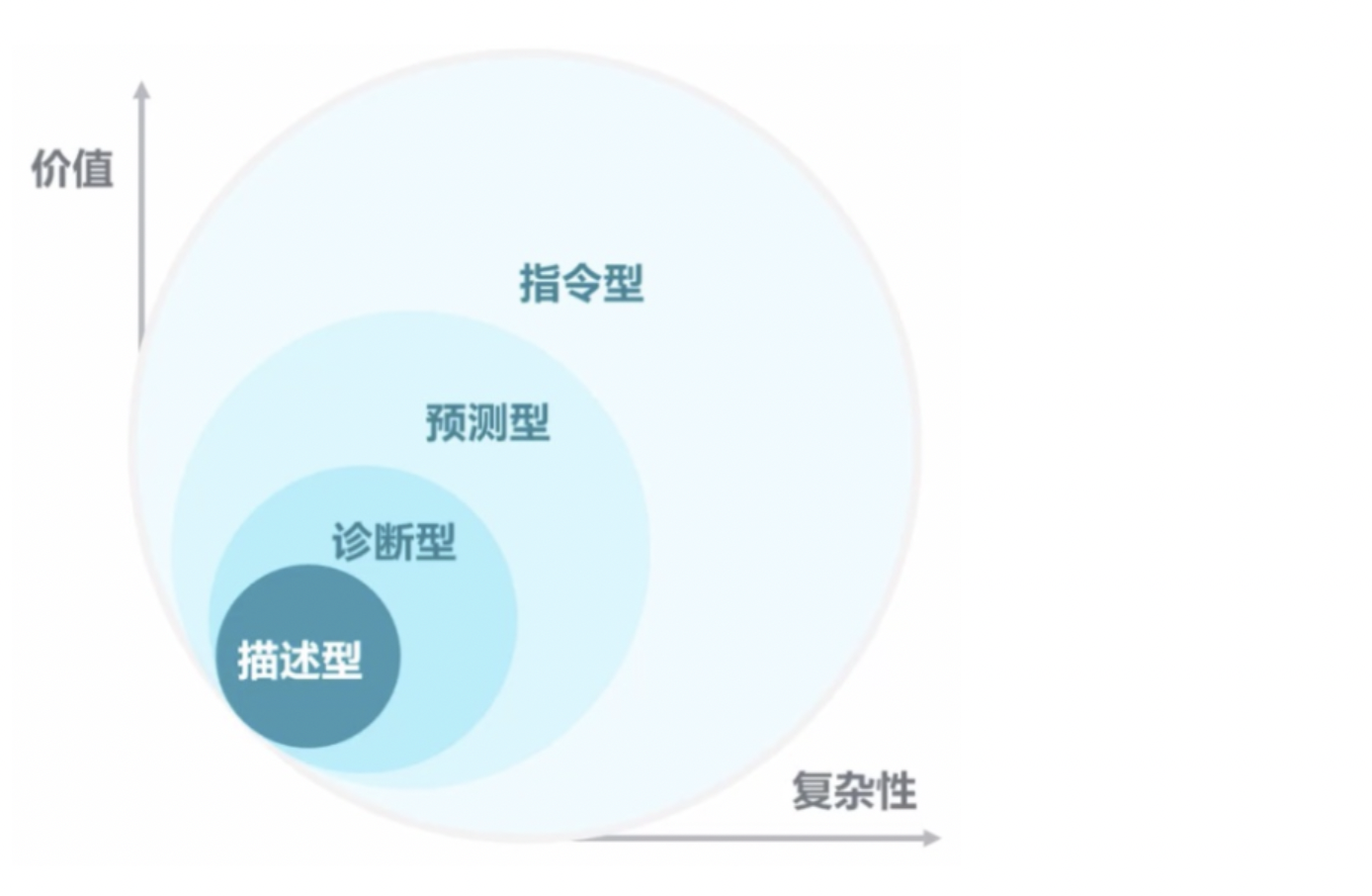
8.统计分析
对数据集进行摘要或描述
- 🌰
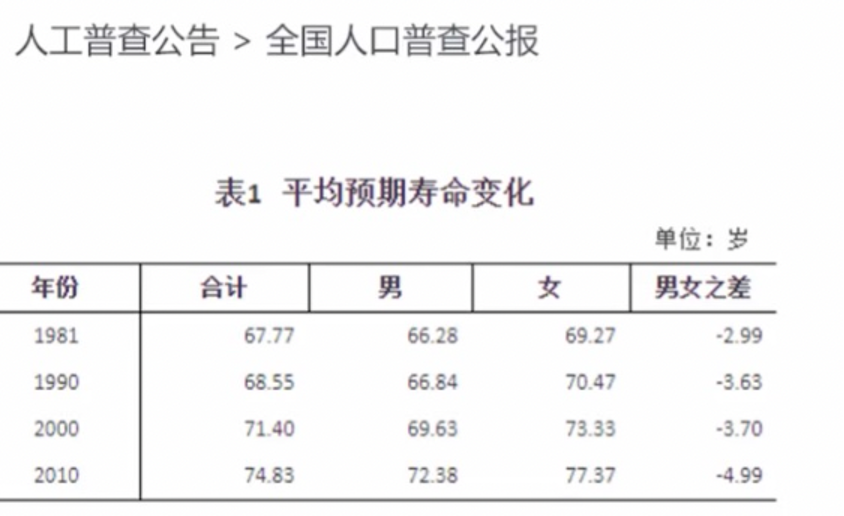
○ 多维分析(钻取、切片、切块、旋转)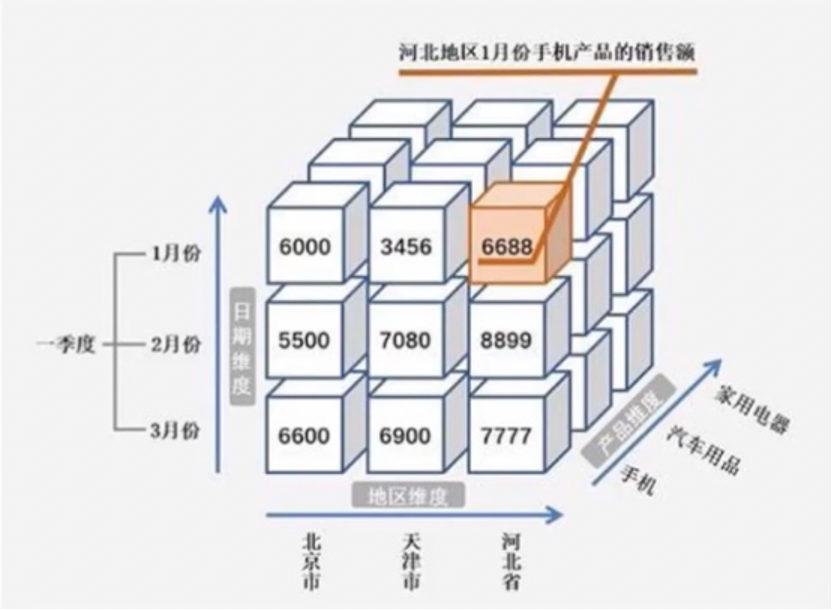
五、数据挖掘技术
1.定义
- 提取隐含在数据中的、人们事前不知道的、但又是潜在有用的信息和知识
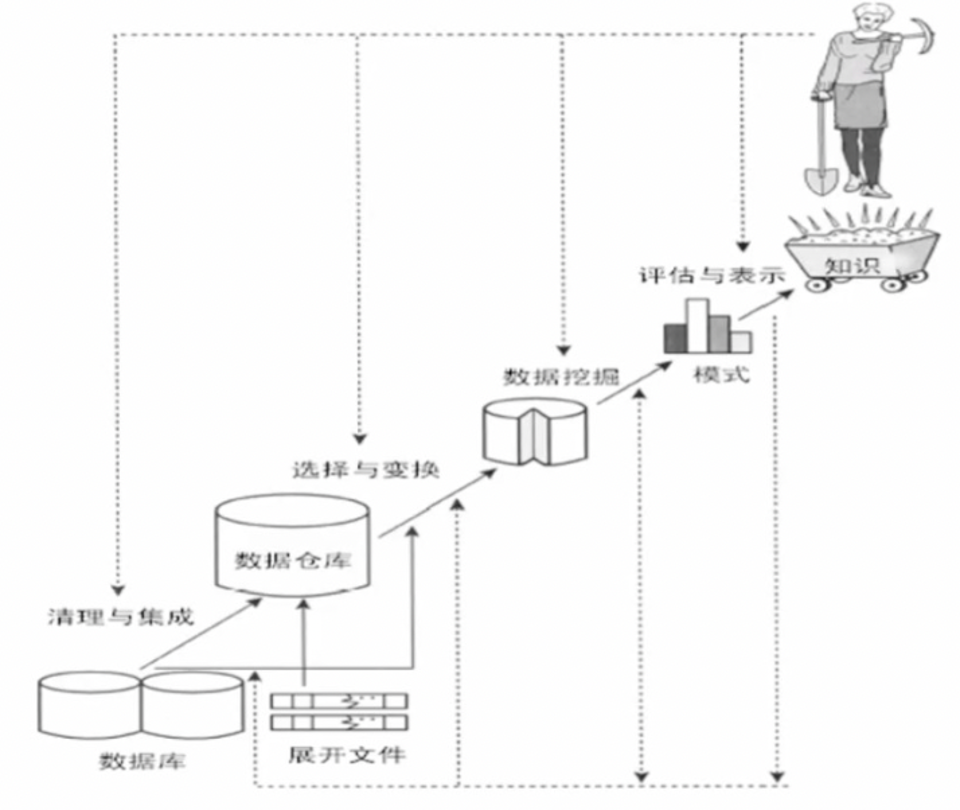
2.算法
○ 以下算法广泛应用于数据挖掘:
C4.5、K-means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、朴素贝叶斯和CART等
3.机器学习
介绍
● 机器获取新知识和新技能,并识别现有知识
● 有监督学习、无监督学习、强化学习、深度学习机器学习技能范畴
● 信息论
● 概率论
● 微积分
● 矩阵论
● 编程过程
● 数据预处理
● 特征工程
● 模拟训练
● 离线/在线预测
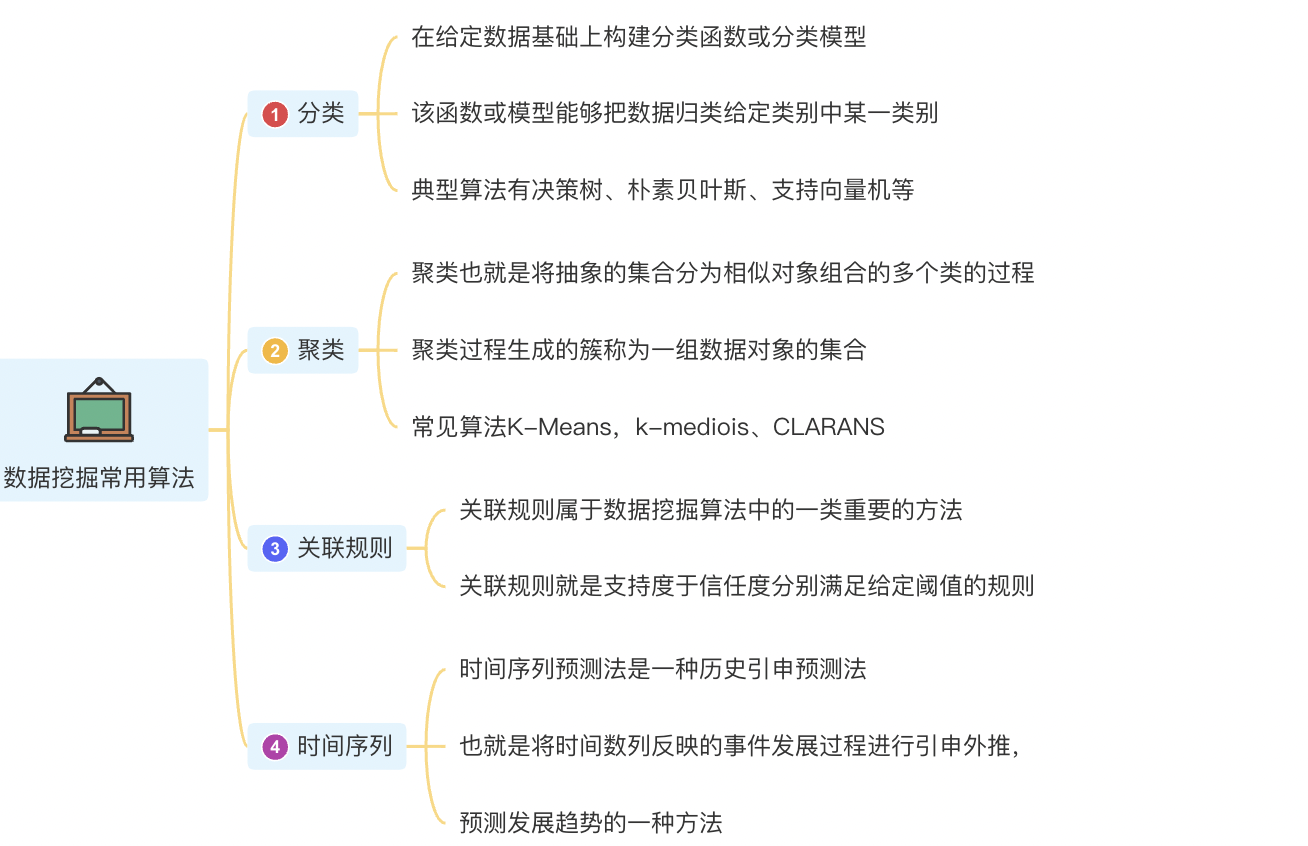
4.数据挖掘常用算法
- 分类、聚类、关联规则、时间序列
六、数据可视化技术
1.数据可视化
■ 利用计算机图形学和图像处理技术,将数据转换为图形或者图像在屏幕上显示出来进行交互处理的理论方法和技术
■ 数据可视化主要旨在借助图形化手段,清晰有效传达与沟通信息
■ 数据可视化随着平台的拓展、应用领域的增加,表现形式的不断变化,从原始的BI统计图表
■ 到不断增加的诸如实时动态效果、地理信息、用户交互等等
■ 数据可视化的概念边界不断扩大
2.常见方法
统计图表|2D、3D区域|时态|多维|分层|网络

3.常见可视化图表

4.图表类型的使用场景
比较
对比各个值之间的差别
○ 柱图
○ 雷达
○ 漏斗
○ 极坐标
○ 旋风漏斗
○ 词云占比
部分占整体的百分比
○ 饼图
○ 漏斗
○ 仪表盘
○ 矩阵树图相关
显示各个值之间的关系
○ 散点
○ 矩阵树图
○ 指标看板
○ 树图
○ 来源去向趋势
数值随维度的变化情况
○ 线图
○ 柱图地理图
数值和地理信息映射图
○ 气泡地图
○ 色彩地图
5.大屏
- 使用大屏来分析并展示庞杂数据的一种数据可视化方式
- 通过丰富的动态、炫目等效果,满足会议展览、业务监控、风险预警、地理信息分析等多种业务等展示需求
🌿至此大数据分析的流程与常用技术笔记📒就介绍完啦~
—— 本文完 · 感谢读到这里的你 🐾 ——