
摘要: 📝本文将为你介绍如何在Hadoop集群上,安装和配置Hive,创建Hive的元数据存储,通过本文的学习,即使你没有太多Hadoop和数据库的经验,也可以轻松搭建Hive集群,搭建均在centos7系统操作,包含zookeeper、hadoop环境配置。
内容结合chatGPT补充知识点,文章以图文方式呈现🌿

一、什么是Hive集群?
简单介绍Hive集群的概念和作用。
Hive
Hive是一个基于Hadoop的数据仓库工具,可以让用户通过SQL语句来查询和分析数据。Hive集群是指由多台计算机组成的集群,用于支持Hive的查询和分析任务。
Hive集群概念
Hive集群是一个强大的数据仓库和分析工具,可以让用户轻松地进行大规模数据处理和分析,提高数据处理的效率和速度。
Hive集群作用
分布式存储和处理:将数据存储在分布式文件系统HDFS中,利用集群中的多台计算机进行数据处理和计算。
大规模数据处理:Hive可以处理PB级别的数据,并提供了丰富的数据处理和分析功能,支持用户通过SQL语句来查询数据。
数据仓库:Hive支持将数据存储在数据仓库中,方便用户进行数据分析和查询。
高可用性和容错性:Hive集群可以通过配置Zookeeper实现高可用性和容错性,确保在某个节点宕机时,集群仍然能够正常工作。
并行处理:Hive可以将大规模数据分成小的数据块进行并行处理,提高了数据处理的效率和速度。
二、Hive集群搭建前的准备工作
⚠️本博文配置的环境是centos7,三个节点(master、slave1、slave2)
三个节点已完成修改主机名、主机映射、免密访问、jdk安装配置
🌱没完成的可以参考这篇文章《云服务器IP映射与ssh免密登录》
本文不提供安装包,所有解压包均在/usr/package277目录下演示
版本说明
| 软件 | 版本 |
|---|---|
| java | jdk1.8.0_221 |
| zookeeper | zookeeper-3.4.14 |
| hadoop | hadoop-2.7.7 |
| hive | apache-hive-2.3.4-bin |
- 关闭防火墙
- Zookeeper集群搭建
- Hadoop集群搭建
- 检查集群状态
1.关闭防火墙
1 | # 关闭防火墙 |
关闭selinux: vi /etc/selinux/config
将以下注释:#SELINUX=enforcing#SELINUXTYPE=targeted
并添加以下内容SELUNX=idsabled
三个节点都要



2.Zookeeper集群搭建
zookeeper安装解压
1 | [root@master java]# mkdir -p /usr/zookeeper && cd /usr/zookeeper |

zookeeper配置系统变量
1 |
|

记得将环境变量传给其他两个节点

修改zookeeper配置文件
Zookeeper的默认配置文件为Zookeeper安装路径下conf/zoo_sample.cfg,将其修改为zoo.cfg
也可以直接vim zoo.zfg
1 |
|

1 | tickTime=2000 |
创建所需数据存储文件夹、日志存储文件夹
1 | [root@master conf]# cd /usr/zookeeper/zookeeper-3.4.14 && mkdir zkdata zkdatalog |
数据存储路径下创建myid,写入对应的标识主机服务器序号
master写1,slave1写2,slave2写3
1 |
|
⚠️记得修改标识主机服务器序号
启动zookeeper服务
1 | # 启动服务,查看进程QuorumPeerMain是否存在 |
⚠️每个节点都需要
- master
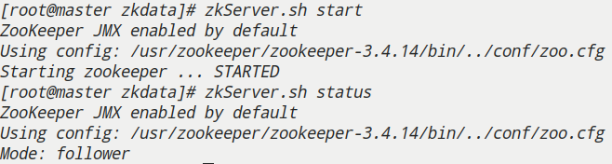
- slave1
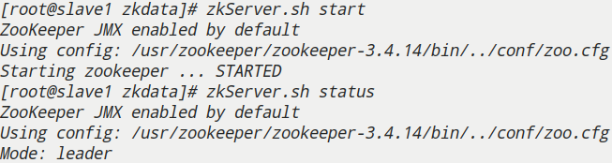
- slave2
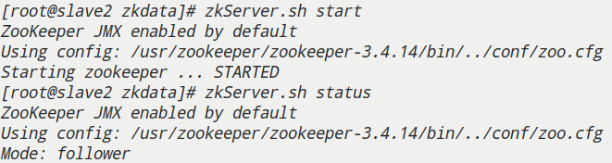
3.Hadoop集群搭建
- Hadoop解压安装
1 | [root@master ~]# mkdir -p /usr/hadoop && cd /usr/hadoop |
- 配置环境变量
1 | hadoop |

别忘了将配置环境传给剩下两个节点

- 修改配置文件
| 配置文件 | 配置对象 | 主要内容 |
|---|---|---|
| hadoop-env.sh | hadoop运行环境 | 用来定义Hadoop运行环境相关的配置信息 |
| core-site.xml | 集群全局参数 | 定义系统级别的参数,包括HDFS URL、Hadoop临时目录等 |
| hdfs-site.xml | HDFS参数 | 定义名称节点、数据节点的存放位置、文本副本的个数、文件读取权限等 |
| mapred-site.xml | MapReduce参数 | 包括JobHistory和应用程序参数两部分,如reduce任务的默认个数、任务所能够使用内存的默认上下限等 |
| yarn-site.xml | 集群资源管理系统参数 | 配置ReduceManager,nodeManager的通信端口等 |

hadoop-env.sh
vim hadoop-env.sh
1 | export JAVA_HOME=/usr/java/jdk1.8.0_221 |

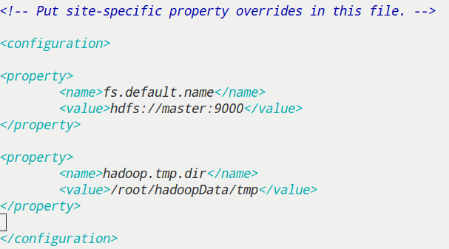
core-site.xml
| 配置参数 | 说明 |
|---|---|
| fs.default.name | 用于指定NameNode的地址 |
| hadoop.tmp.dir | Hadoop运行时产生文件等临时存储目录 |
vim core-site.xml
1 | <property> |
hdfs-site.xml
| 配置参数 | 说明 |
|---|---|
| dfs.replication | 数据块副本的数量 |
| dfs.namenode.name.dir | NameNode在本地文件系统中持久存储命名空间和事物日志的路径 |
| dfs.datanode.data.dir | DataNode在本地文件系统中存放块的路径 |
| dfs.permissions | 集群权限系统校验 |
| dfs.datanode.use.datanode.hostname | datanode之间的通信的通过域名方式- |
vim hdfs-site.xml
1 | <property> |

yarn-env.sh
vim yarn-env.sh
1 | export JAVA_HOME=/usr/java/jdk1.8.0_221 |

yarn-site.xml
| 配置参数 | 说明 |
|---|---|
| yarn.resourcemanager.admin.address | 用于指定RM管理界面等地址(主机端口) |
| yarn.nodemanager.aux-services | mapreduce获取数据的方式,指定在进行mapreduce作业时,yarn使用mapreduce_shuffle混洗技术。这个混洗技术是hadoop的一个核心技术,非常重要 |
| yarn.nodemanager.auxservices.mapreduce.shuffle.class | 用于指定混洗技术对应的字节码文件,值为org.apache.hadoop.mapred.ShuffleHandler |
vim yarn-site.xml
1 | <property> |

mapred-site.xml
| 配置参数 | 说明 |
|---|---|
| mapreduce.framework.name | 指定执行MapReduce作业的运行时框架。熟悉值可以是local,class或yarn |
1 | [root@master hadoop]# cp mapred-site.xml.template mapred-site.xml |
1 | <property> |

设置节点文件
1 | [root@master hadoop]# echo master >master |

记得将hadoop文件夹传给其他两个节点
格式化(master)
hadoop namenode -format
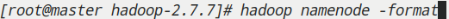
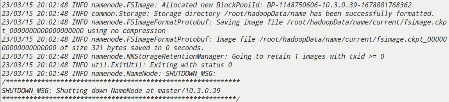
4.检查集群状态
启动Hadoop集群查看各节点服务
start-all.sh
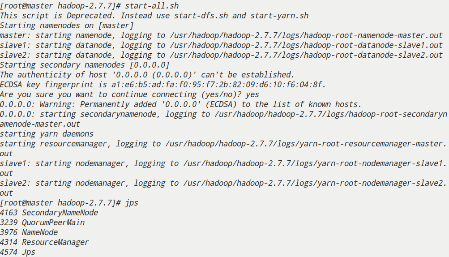
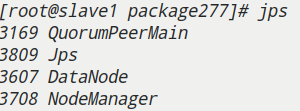
jps查看其他节点
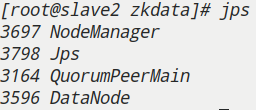
查看集群状态是否正常
hdfs dfsadmin -report
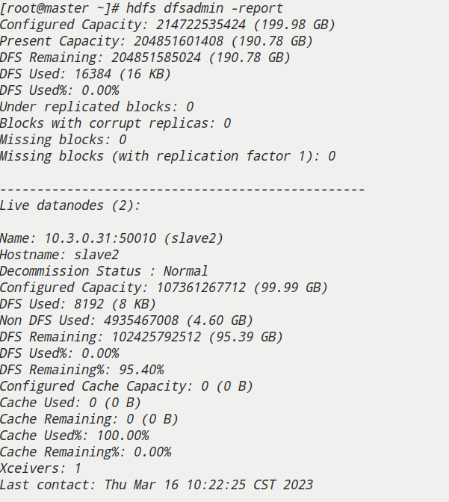
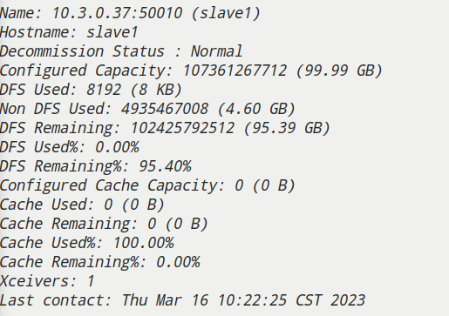
三、Hive集群搭建的详细步骤
1. Mysql数据库配置(slave2)
- mysql-community-server
本环境中已经安装mysql-community-server
Linux安装mysql-community-server文档
1 | #关闭mysql开机自启服务 |
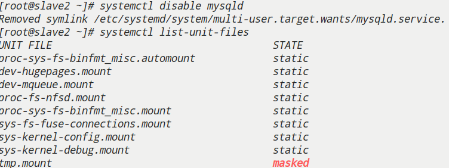
- 开启MySQL服务
1 | [root@slave2 usr]# systemctl start mysqld |
- 生成初临时密码
判断mysqld.log日志下是否生成初临时密码
1 | [root@slave2 usr]# grep "temporary password" /var/log/mysqld.log |


- 设置本地密码
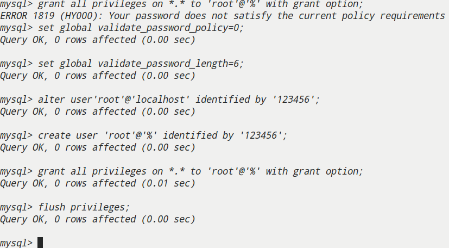
设置mysql数据库本地root用户密码为123456
1 | mysql> set global validate_password_policy=0; |
2. hive基础环境配置(master、slave1)
hive解压安装
1 | [root@master usr]# mkdir -p /usr/hive && cd /usr/hive |

hive配置环境变量
1 | hive |
剩下两个节点也要
修改HIVE运行环境
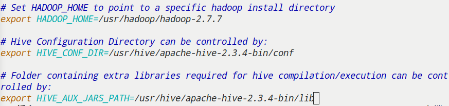
配置Hadoop安装路径HADOOP_HOME
1 | [root@master hive]# cd $HIVE_HOME/conf |
1 | 配置hadoop安装路径 |
解决jline的版本冲突
jline是一个Java命令行输入输出(IO)库,常常用于控制台交互式应用程序中。在Hive配置中,也用到了jline,尤其是在启动Hive CLI(命令行界面)时。然而,在不同版本的软件包中,可能会包含不同的jline版本,这会导致版本冲突问题。为了避免这个问题,我们需要解决Hive与其他软件包之间的jline版本冲突。
将$HIVE_HOME/lib/jline-2.12.jar同步至$HADOOP_HOME/share/hadoop/yarn/lib/下
1 | [root@master conf]# cp $HIVE_HOME/lib/jline-2.12.jar $HADOOP_HOME/share/hadoop/yarn/lib/ |
⚠️记得把master上的hive传给slave1

slave1上也要解决jline的版本冲突

Hive服务器端是数据存储和处理的主机,而Hive客户端则是与服务器交互的用户界面
就像我们去餐馆点餐时,餐馆厨房是负责制作菜品的地方,而菜单则是我们与餐馆进行交互并点选要点的工具。
3. 服务器端配置(slave1)
配置HIVE元数据至MySQL
拷贝驱动
驱动JDBC拷贝至hive安装目录对应lib下(依赖包存放于/usr/package277/)
1 | [root@slave1 apache-hive-2.3.4-bin]# cp /usr/package277/mysql-connector-java-5.1.47-bin.jar /usr/hive/apache-hive-2.3.4-bin/lib/ |
配置slave1的hive-site.xml
1 | cd $HIVE_HOME |

添加如下内容
1 | <configuration> |

4. 客户端配置(master)
配置master的hive-site.xml
1 | cd $HIVE_HOME |
添加如下内容
1 | <configuration> |

5. 启动hive
服务器端slave1
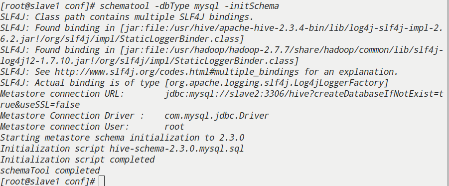
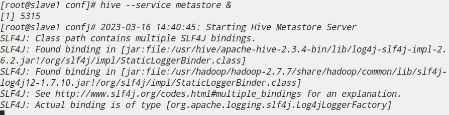
服务器端初始化数据库,启动metastore服务
1 | [root@slave1 apache-hive-2.3.4-bin]# schematool -dbType mysql -initSchema |
客户端master
客户端开启进入hive,创建hive数据库
1 | [root@master; apache-hive-2.3.4-bin]# hive |
1 | hive> create database hive; |
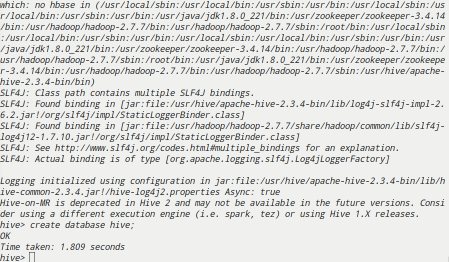
四、测试Hive集群
- 地址在使用
1 | [root@slave1 apache-hive-2.3.4-bin]# netstat -alnp | grep 9083 |
- 初始化失败
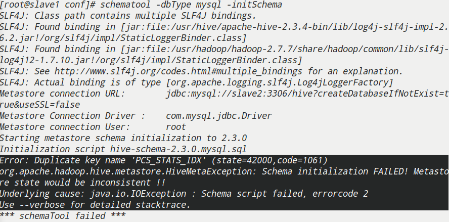
解决
测试Hive的高可用性和负载均衡性
要测试Hive的高可用性和负载均衡性,需要先搭建一个Hive集群,并使用ZooKeeper进行管理。
下面是一些测试Hive高可用性和负载均衡性的方法:
模拟故障:在集群中的一个节点上停止Hive服务或ZooKeeper服务,然后观察集群的反应。如果Hive集群的配置和ZooKeeper配置正确,则其他节点会接管故障节点的工作,从而保证服务的高可用性。
并发访问:使用多个客户端同时访问Hive集群中的表,观察查询的响应时间和负载情况。如果Hive集群的配置和ZooKeeper配置正确,则Hive会将负载均衡到不同的节点上,以提高查询的并发性能。
数据负载测试:在Hive集群中加载大量数据,然后执行一些复杂的查询,观察查询的响应时间和负载情况。如果Hive集群的配置和ZooKeeper配置正确,则Hive会将查询均匀地分布到不同的节点上,从而提高查询的并发性能。
故障转移测试:在Hive集群中启用故障转移功能,并模拟故障,观察集群的反应。如果Hive集群的配置和ZooKeeper配置正确,则当一个节点失败时,Hive会自动将查询和其他任务转移到可用的节点上,从而保证服务的高可用性。
资源管理测试:在Hive集群中使用资源管理器,对查询进行限制和管理,以确保集群的负载均衡和稳定性。可以使用YARN等资源管理器进行测试。
综上所述,测试Hive的高可用性和负载均衡性是非常重要的,可以确保Hive集群的稳定性和性能。
五、注意事项和问题解决方法
常见问题及解决方法:
集群性能问题:可能是由于配置不当、硬件性能不足或数据量过大等原因引起。可以通过增加集群节点、调整配置参数或者优化查询语句等方法来提升性能。
数据倾斜问题:在数据分布不均衡的情况下,会导致部分节点的负载过大,从而影响整个集群的性能。解决方法包括数据预处理、增加节点、调整数据切分规则等。
安全问题:由于Hive集群处理的是敏感数据,因此安全性是非常重要的。可以通过开启Kerberos认证、设置访问权限、加密通信等方法来保证数据的安全性。
Hive元数据问题:Hive元数据是集群的核心数据,如果发生了意外删除或者丢失,会导致集群无法正常工作。可以通过备份元数据、设置元数据的持久化存储等方法来避免这种情况的发生。
保证Hive集群的安全性和稳定性的方法:
安全性:开启Kerberos认证,限制访问权限,加密通信等方法可以保证数据的安全性。
稳定性:Hive集群的稳定性可以通过以下几个方面来保证:
配置合理的硬件:集群的硬件要求很高,必须满足存储、计算和网络的需求。
定期维护:集群需要定期维护,包括清理数据、备份数据、检查元数据等。
自动化监控:使用监控系统对集群进行自动化监控,及时发现异常并进行处理。
容错处理:在出现故障时,要能够快速地恢复集群,并保证数据的完整性。
隔离性:在集群运行过程中,不同的任务之间需要隔离,防止彼此干扰。可以通过容器化、虚拟化等技术来实现任务隔离。
六、总结
在搭建Hive集群时,需要遵循以下步骤:
配置Hadoop集群:Hive需要在Hadoop上运行,因此需要先搭建Hadoop集群。
安装Hive:根据实际需求选择Hive版本,下载并解压。
配置Hive:根据实际需求修改Hive配置文件hive-site.xml,包括数据库、元数据、HiveServer2等参数。
启动Hive集群:依次启动Zookeeper、Hadoop集群、Hive元数据服务、HiveServer2。
测试Hive:使用Hive提供的客户端工具或者其他第三方工具,测试Hive的功能和性能。
在搭建Hive集群时需要注意以下事项:
确保Hadoop集群正常运行:Hive需要在Hadoop上运行,因此需要先确保Hadoop集群正常运行。
配置正确的元数据存储:Hive的元数据存储在RDBMS中,需要确保配置正确的数据库连接信息。
配置HiveServer2的安全性:HiveServer2默认是不安全的,需要配置安全验证信息。
确保集群安全性:在使用Hive集群时,需要确保集群的安全性,包括网络安全、权限管理等。
定期备份数据和元数据:Hive的数据和元数据是非常重要的,需要定期备份以避免数据丢失。
在实际使用Hive集群时,需要注意以下事项:
合理使用资源:Hive集群需要大量的资源,需要合理规划和使用资源。
避免长时间运行的查询:长时间运行的查询会占用集群资源,导致其他查询的性能下降。
定期优化表和查询:对于经常使用的表和查询,需要进行优化以提高性能。
监控集群运行情况:定期监控集群的运行情况,及时发现和解决问题。
🌱至此如何搭建Hive集群已经结束啦,祝你成功!
—— 本文完 · 感谢读到这里的你 🐾 ——