
摘要: 本文主要记录📝在华为云服务器里Hadoop HA安装配置(HDFS的HA和YARN的HA、zookeeper相关配置介绍),以及补充学到的知识点,文章以图文形式呈现,超详细哦🌿。
一、前言
HDFS高可用实现原理
主要配置了活动-备用(active-standby)NameNode。当活动NameNode失效,备用NameNode就会接管它的任务并响应来自客户端的服务请求,不会有任何明显中断。
ZooKeeper介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件,在大数据领域得到了广泛的应用。它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作,为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper的基本运转流程:
1.选举Leader
2.同步数据
3.选举Leader过程中算法有很多,但要达到的选举标准是一致的。
4.Leader要具有最高的执行ID,类似root权限
5.集群中大多数的机器得到响应并接受选出的Leader
二、环境准备
三台服务器(master、slave1、slave2)
各节点完成了IP映射与ssh免密
🌱没完成的可以看下这篇文章《云服务器IP映射与ssh免密登录》配置好了JDK
🌱没完成的可以看下这篇文章《Hadoop完全分布式配置》了解Hadoop基础知识
🌱想了解的可以看下这篇文章《Hadoop知识点汇总》
Hadoop HA的最终规划
| master | slave1 | slave2 |
|---|---|---|
| Zookeeper | Zookeeper | Zookeeper |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| NameNode | NameNode | - |
| ResourceManager | ResourceManager | - |
| ZKFC | ZKFC | - |
Secondary NameNode的角色被备用NameNode所包含,备用NameNode为活动的NameNode命名空间设置周期性检查点
三、配置Zookeeper
1.下载zookeeper
首先从官网下载zookeeper,这里以Zookeeper3.4.10为例,并上传到master的/usr/local目录下
1 | [root@master ~]# cd /usr/local |
2.配置zookeeper环境变量
在profile文件末尾添加zookeeper的环境变量(不可以有空格):
1 | [root@master ~]# vim /etc/profile |
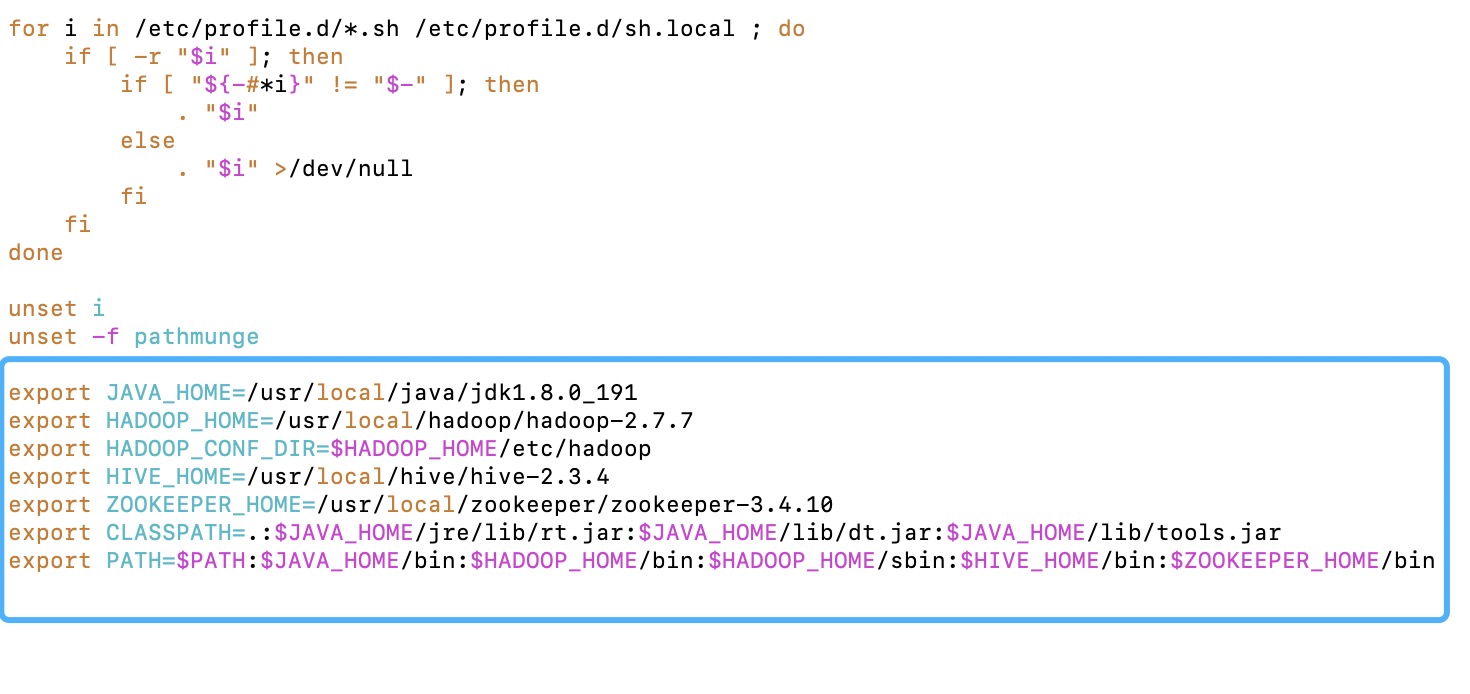
最后:source /etc/profile使刚刚的配置生效
1 | [root@master ~]# source /etc/profile |
3.配置zoo.cfg文件
将zoo.cfg配置文件新增如下配置:
1 | dataDir配置项值,修改为如下值(可根据实际情况改变): |
修改后配置文件如下图所示: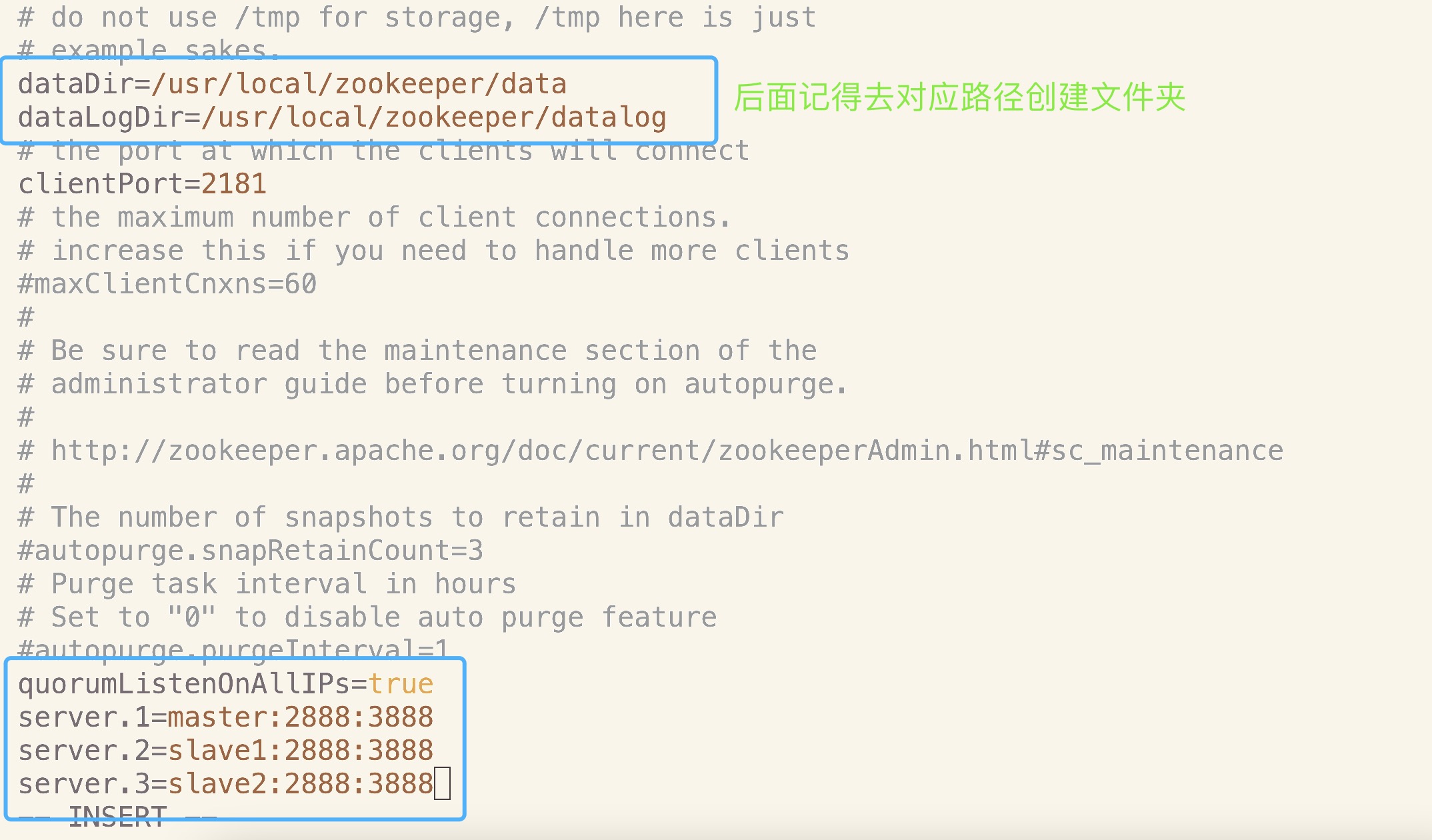
4.配置myid文件
指定myid。在配置项dataDir指定目录下,新建myid文件,并写入数字1(即第1个服务器节点),使用以下命令:
echo 1 > /usr/local/zookeeper/data/myid

⚠️没有的文件夹需要自己手动创建
5.配置另外两个节点
1 | 把上面配置好的zookeeper文件夹直接传到两个子节点 |
⚠️在两个子节点上把myid文件里面的 1 给分别替换成 2 和 3
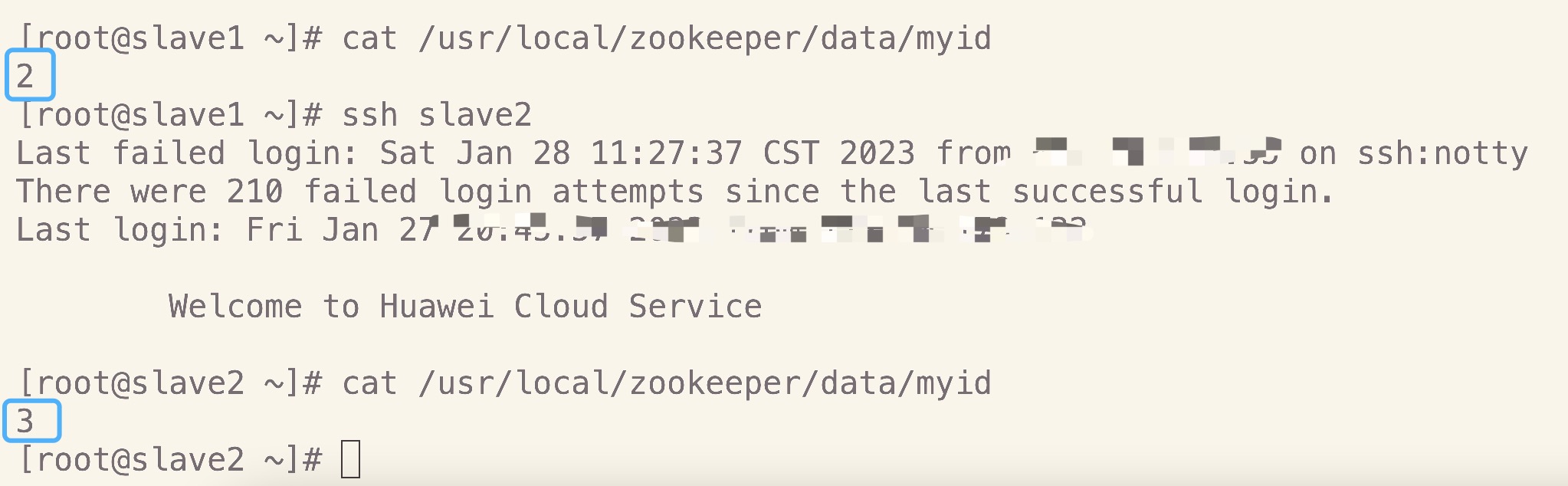
6.配置项介绍
基础配置
- tickTime:Client和Server通信心跳数
Zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每隔tickTime的时间就会发送一个心跳。tickTime以毫秒为单位
The number of milliseconds of each tick
tickTime=2000
- initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)
The number of ticks that the initial
synchronization phase can take
initLimit=10
- syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)
The number of ticks that can pass between
sending a request and getting an acknowledgement
syncLimit=5
- dataDir:数据文件目录
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
the directory where the snapshot is stored.
do not use /tmp for storage, /tmp here is just example sakes.
dataDir=/usr/local/zookeeper/data
- clientPort:客户端连接端口
客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口,接受客户端的访问请求。
the port at which the clients will connect
clientPort=2181
- maxClientCnxns:客服端最大连接数
默认值是60,一个客户端能够连接到同一个服务器上的最大连接数,根据IP来区分。如果设置为0,表示没有任何限制。设置该值一方面是为了防止DoS攻击
the maximum number of client connections.
increase this if you need to handle more clients
maxClientCnxns=60
高级配置
一般情况下,不需要更改或添加以下配置,根据用户实际需求再添加或修改即可
dataLogDir:用于配置ZooKeeper服务器存储事务日志文件的路径globalOutstandingLimit:限制系统中未处理的请求数量不超过globalOutstandingLimit设置的值。默认的限制是1000preAllocSize:用于配置ZooKeeper事务日志文件预分配的磁盘空间大小。默认的块大小是64MsnapCount: ZooKeeper将事务记录到事务日志中。当snapCount 个事务被写到一个日志文件后,启动一个快照并创建一个新的事务日志文件。snapCount的默认值是100000traceFile:如果定义了该选项,那么请求将会记录到一个名为 traceFile.year.month.day的跟踪文件中autopurge.snapRetainCount: 当启用自动清理功能后, ZooKeeper将只保留autopurge.snapRetainCount个最近的数据快照(dataDir)和对应的事务日志文件(dataLogDir),其余的将会删除掉。默认值是3,最小值也是3autopurge.purgeInterval:用于配置触发清理任务的时间间隔, 以小时为单位。要启用自动清理,可以将其值设置为一个正整数(大于1)。默认值是0syncEnabled: 和参与者一样,观察者现在默认将事务日志以及数据快照写到磁盘上, 这将减少观察者在服务器重启时的恢复时间。将其值设置为false可以禁用该特性。默认值是trueminSessionTimeout:服务器允许客户端会话的最小超时时间,以毫秒为单位。默认值是2倍的tickTimemaxSessionTimeout:服务器允许客户端会话的最大超时时间,以毫秒为单位。默认值是20倍的tickTime
日志输出配置
ZooKeeper的日志输出信息都打印到了zookeeper.out文件中,这样输出路径没有办法控制。
通过修改zkEnv.sh可以达到控制日志输出信息的位置。使用如下命令
vi /usr/local/zookeeper/zookeeper-3.4.10/bin/zkEnv.sh
根据实际情况修改ZOO_LOG_DIR的值并保存即可
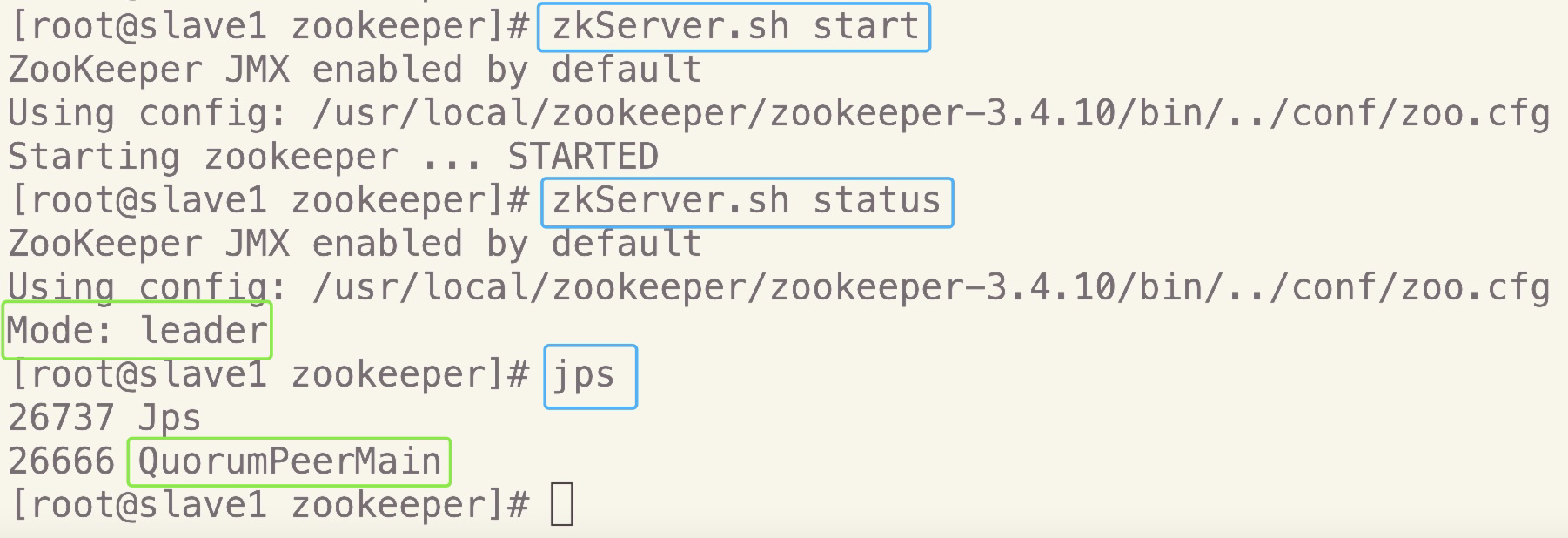
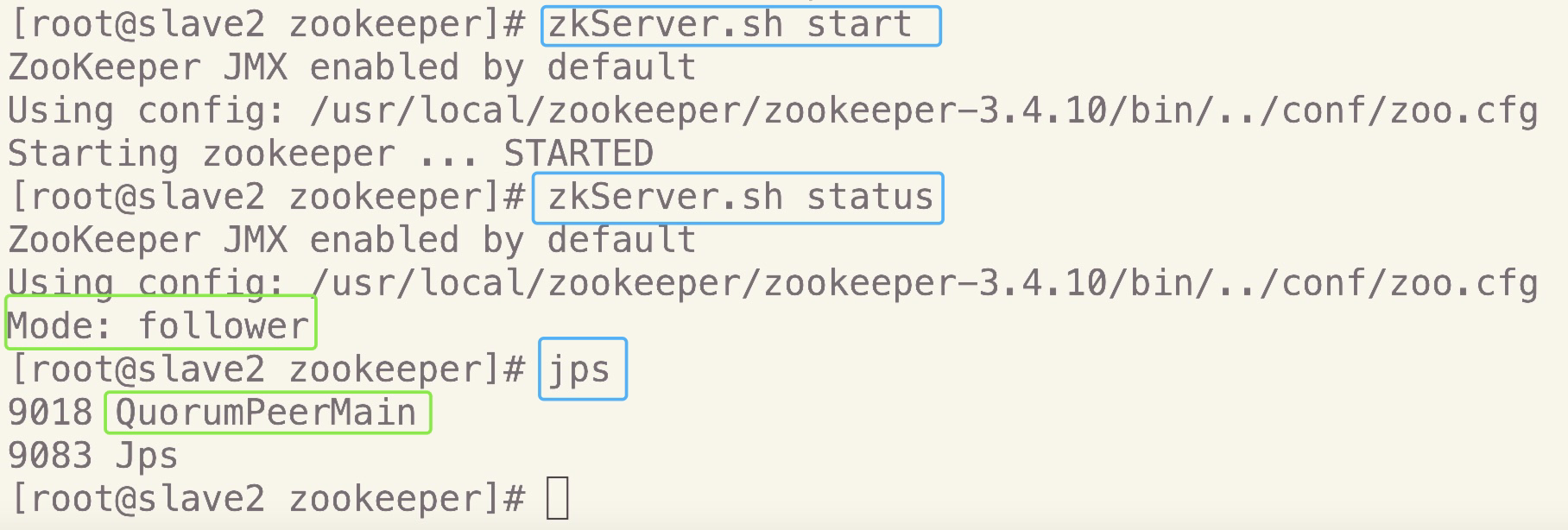
7.测试Zookeeper
在三个节点上分别执行命令,启动服务:
zkServer.sh start在三个节点上分别执行命令,查看状态:
zkServer.sh status
正确结果应该是:三个节点中其中一个是leader,另外两个是follower在三个节点上分别利用
jps命令查看当前进程:
检查三个节点是否都有QuromPeerMain进程
如下图所示安装配置成功:master
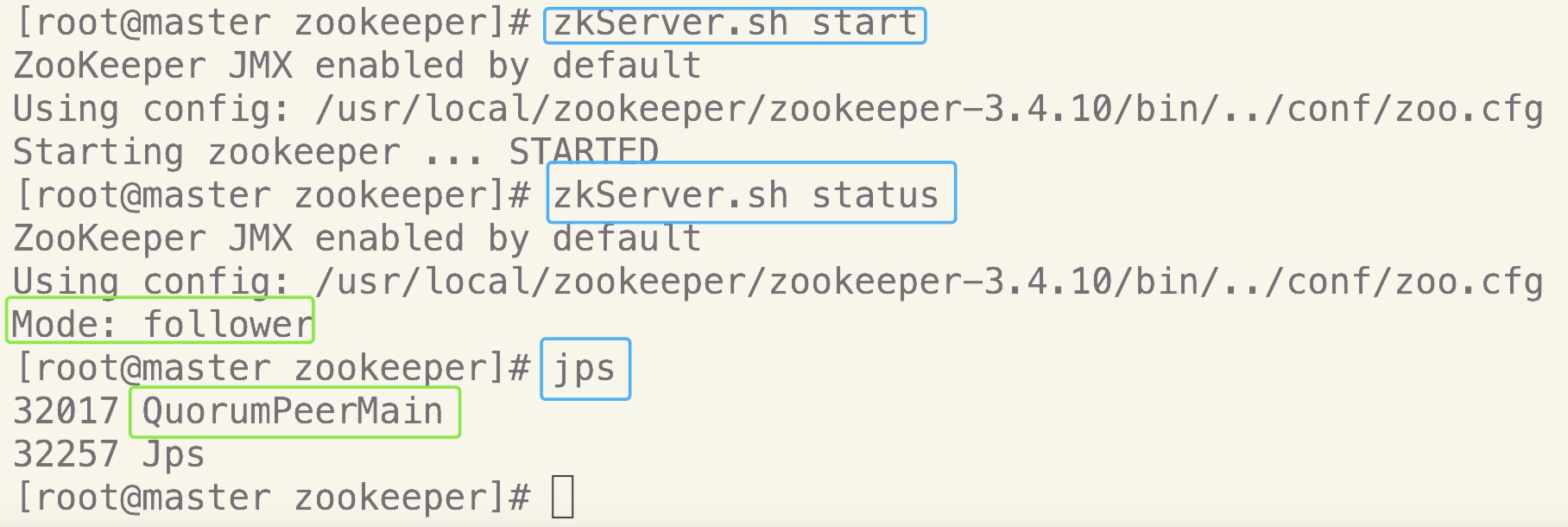
slave1
slave2
四、配置Hadoop HA集群
因为在Hadoop完全分布式的基础上进行配置,准备环境(包括hadoop-env.sh、slaves、配置Hadoop环境变量)详情请参照《Hadoop完全分布式配置》
接下来直接配置Hadoop HA🍃
1.core-site.xml
1 | <!-- Put site-specific property overrides in this file. --> |

2.hdfs-site.xml
1 | <!-- Put site-specific property overrides in this file. --> |


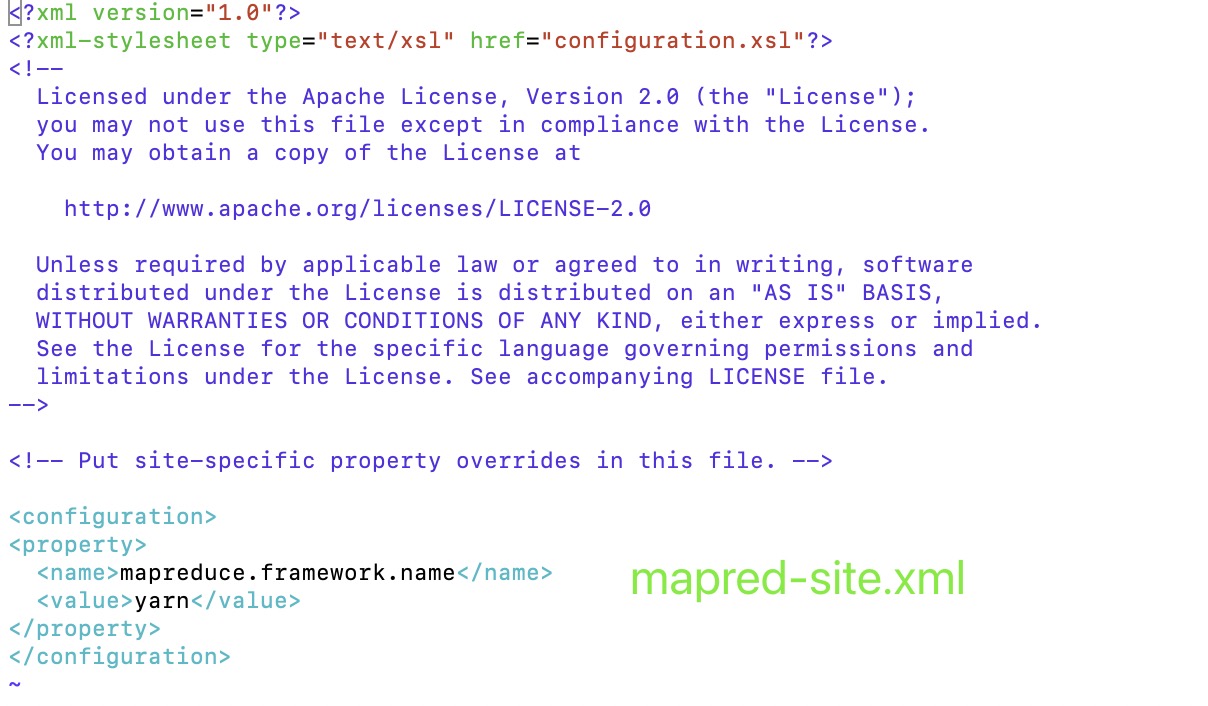
3.mapred-site.xml
1 | <configuration> |
4.yarn-site.xml
1 | <configuration> |

创建文件夹
⚠️配置的这几个地方的文件夹要自己手动创建好


三个节点都要创建别忘了噢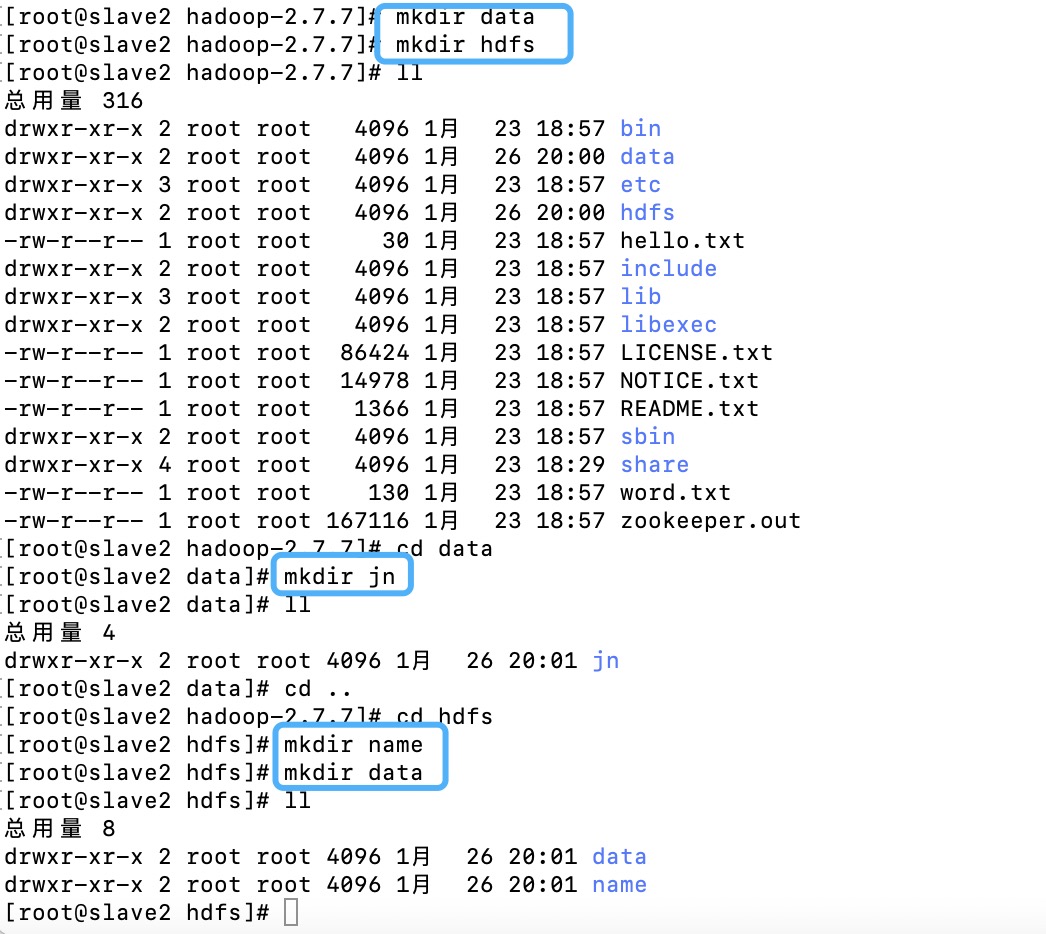
五、Hadoop HA集群启动
1.启动Zookeeper集群
⚠️在测试zookeeper的时候启动过了,这里就不用重复启动了,直接jps查看
在三个节点上分别执行命令,启动服务:
zkServer.sh start在三个节点上分别执行命令,查看状态:
zkServer.sh status
正确结果应该是:三个节点中其中一个是leader,另外两个是follower在三个节点上分别利用
jps命令查看当前进程:
检查三个节点是否都有QuromPeerMain进程关闭服务
zkServer.sh stop
2.启动journalnode集群
⚠️在各个journalnode节点上启动journalnode服务
不启动journalnode就格式化namenode的话会报错
hadoop-daemons.sh start journalnode
可以jps查看
- master
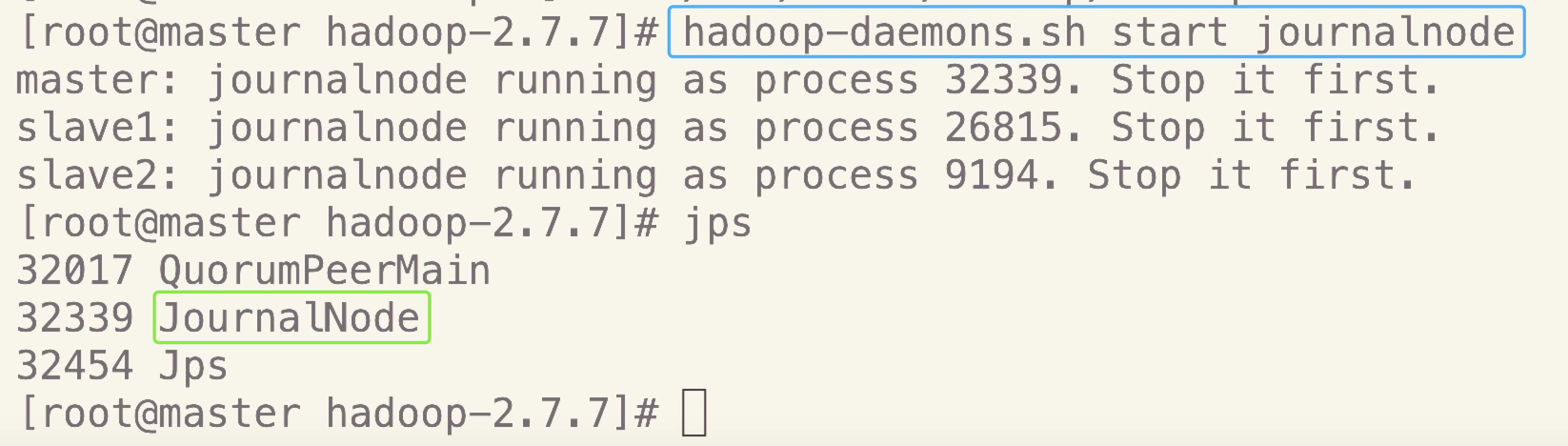
- slave1
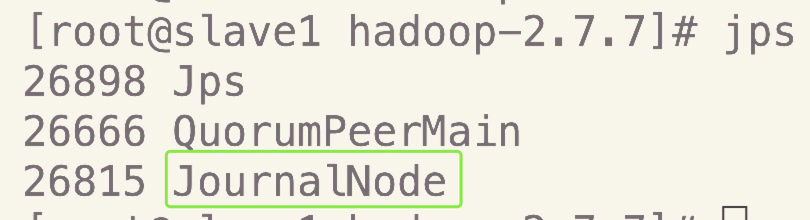
- slave2
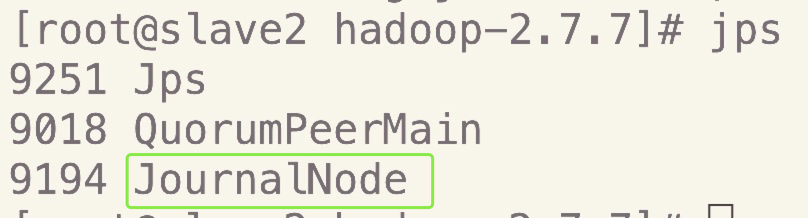
3.格式化zkfc,在zookeeper中生成ha节点
在master执行如下命令,完成格式化
hdfs zkfc –formatZK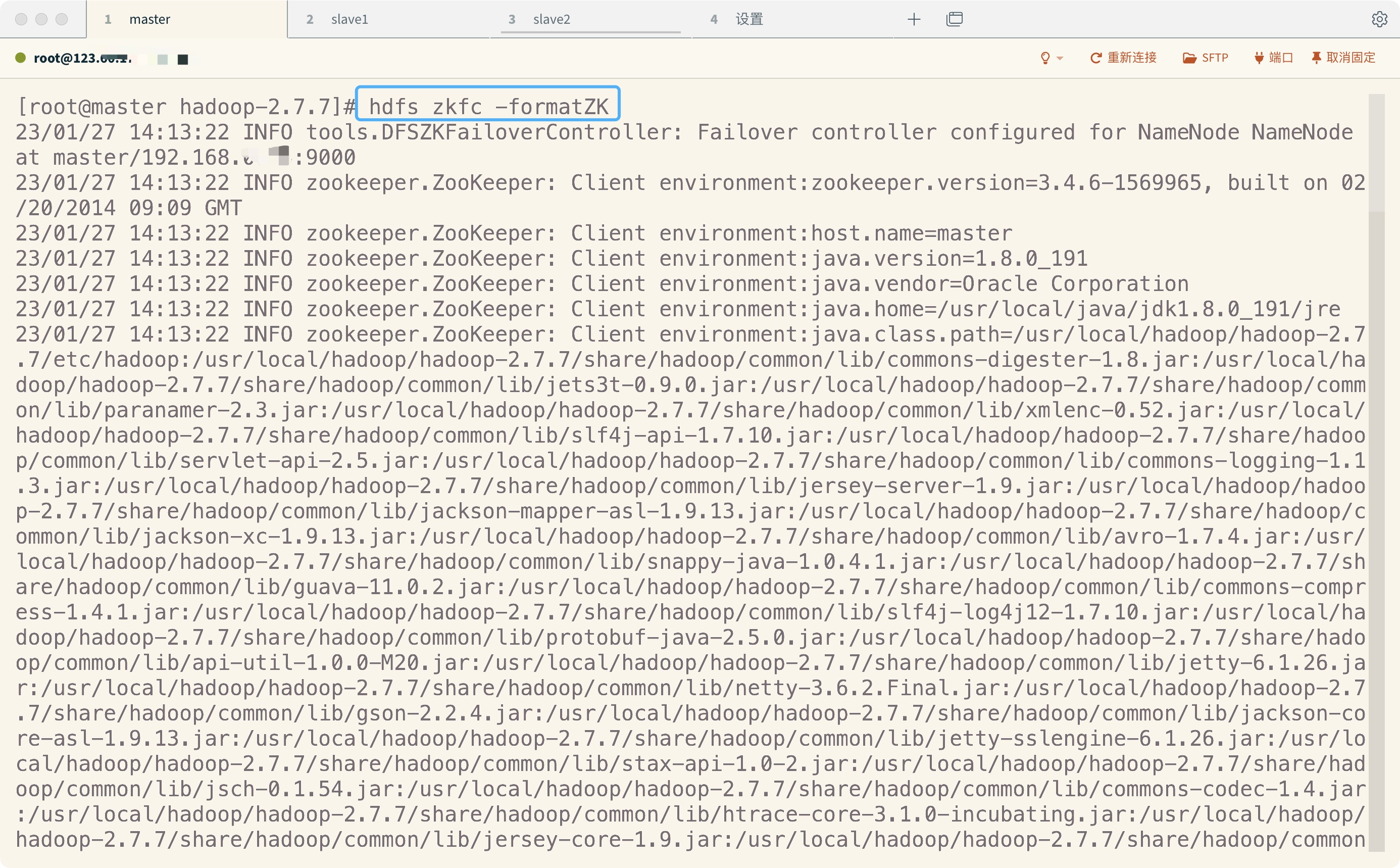
4.格式化hdfs
在master执行如下命令,完成格式化
hadoop namenode –format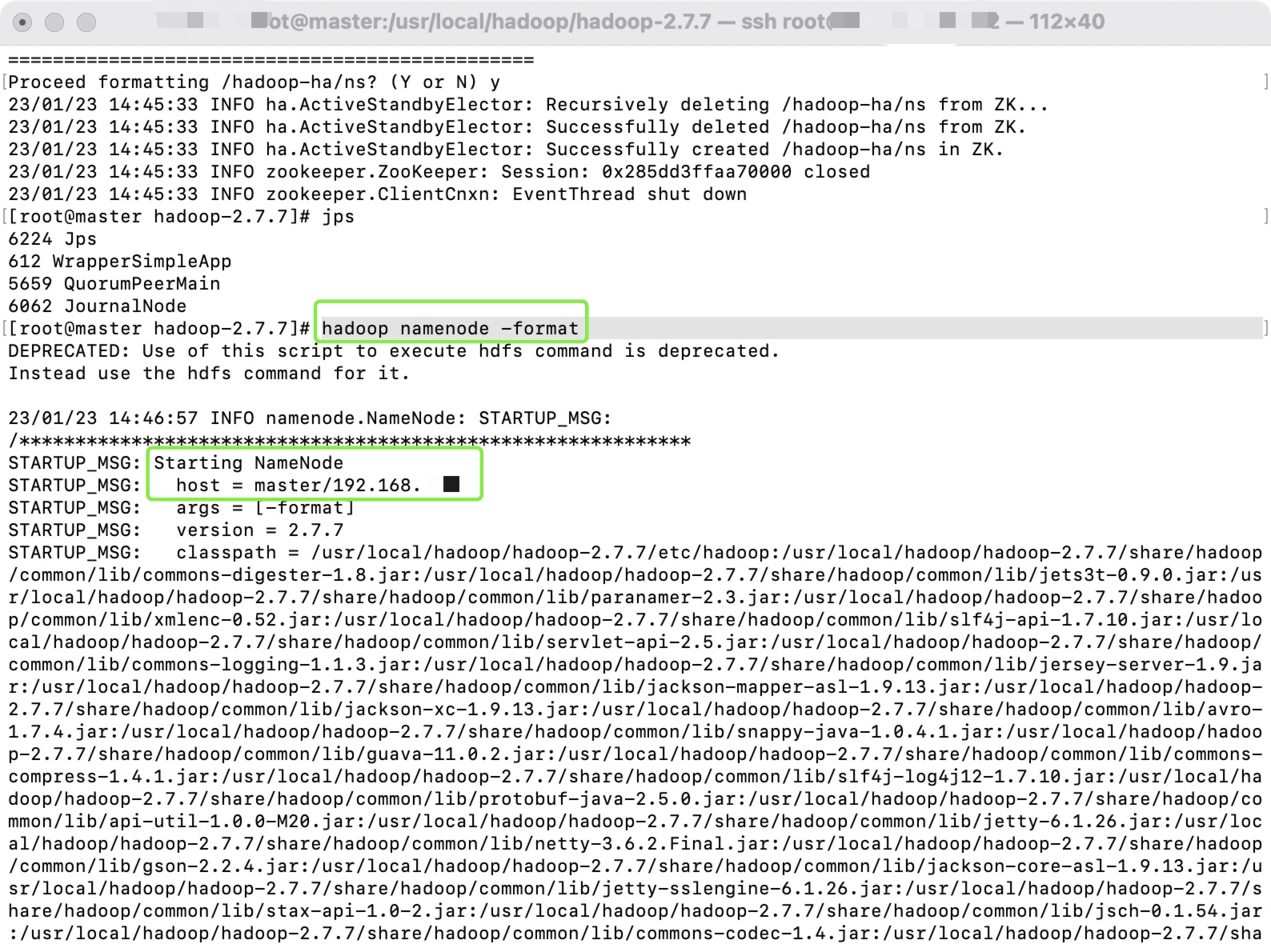
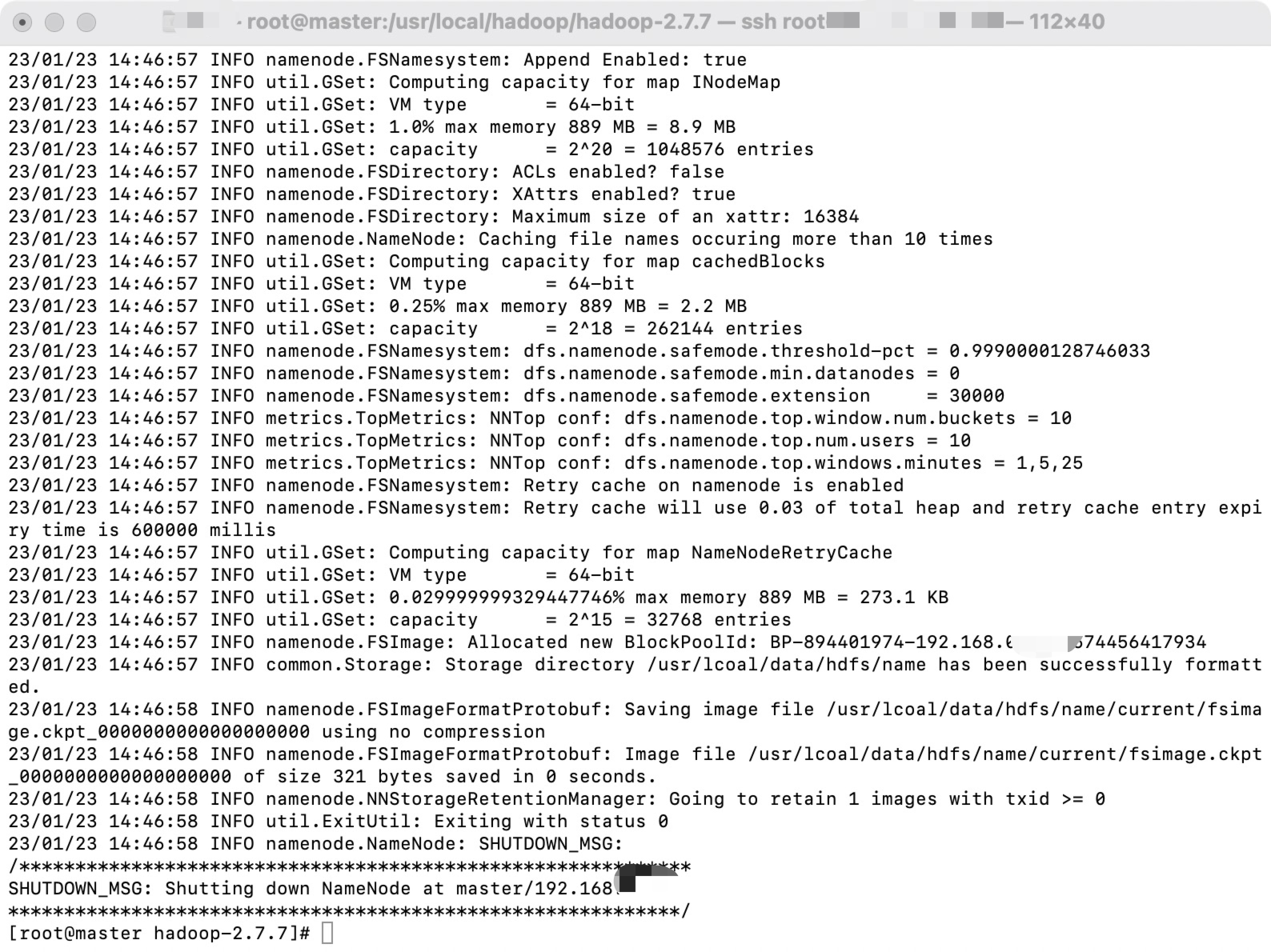
5.启动NameNode
在mast1上启动active节点,在liuyazhuang145上执行如下命令
hadoop-daemon.sh start namenode
在slave1上同步namenode的数据,同时启动standby的namenode
命令如下:
- 把master的NameNode的数据同步到slave1上
hdfs namenode -bootstrapStandby
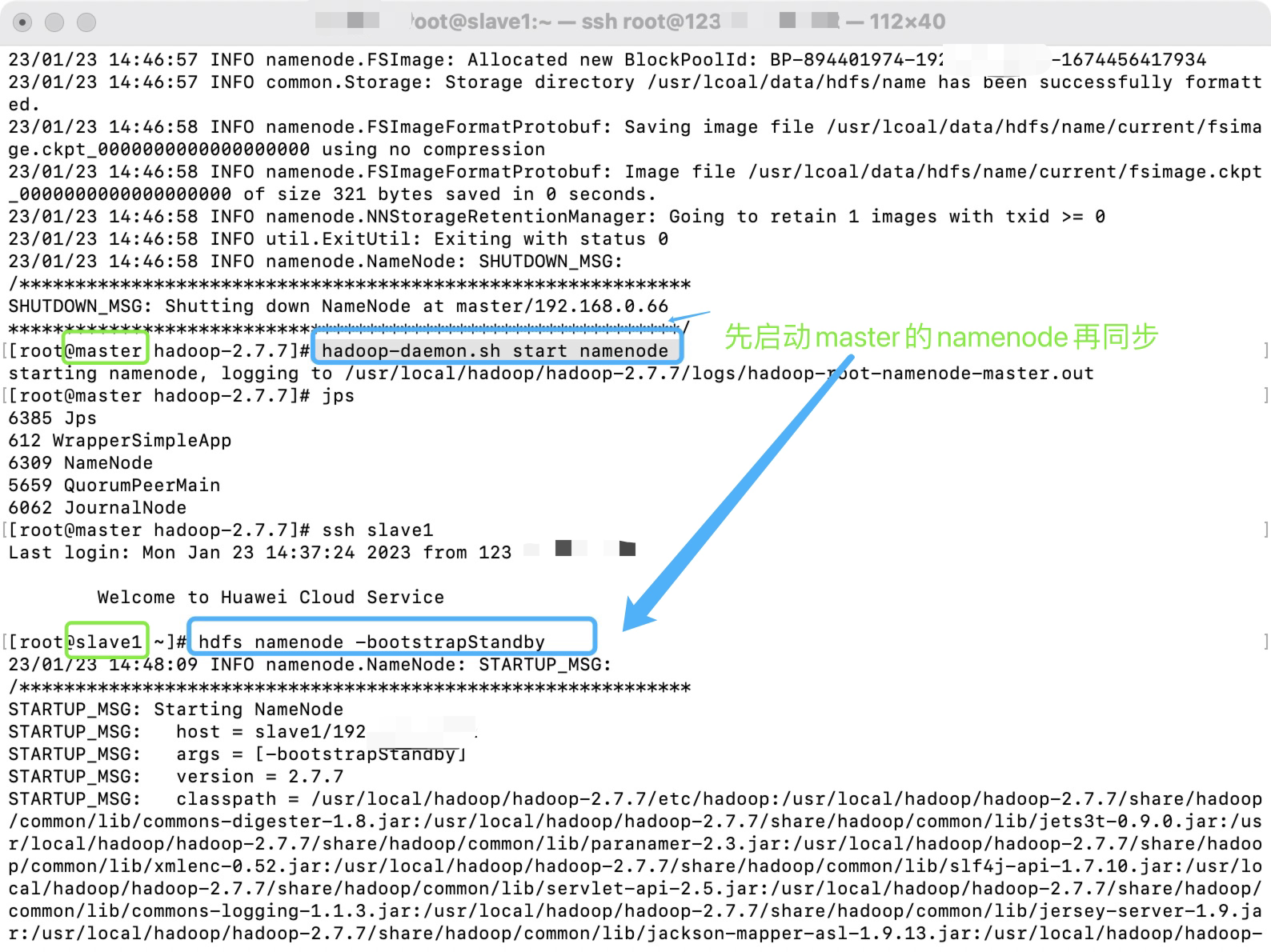
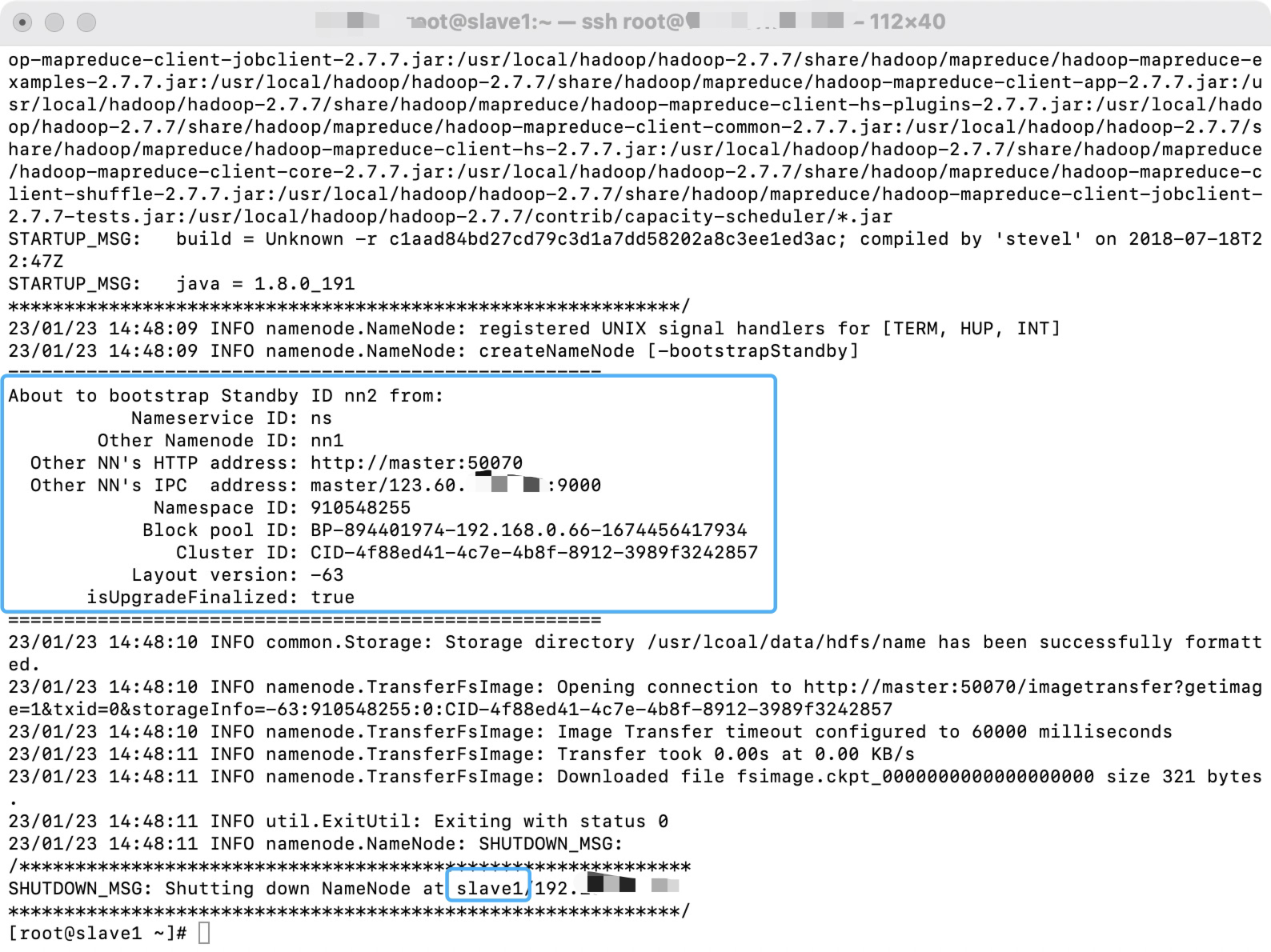
- 启动slave1的namenode作为standby
hadoop-daemon.sh start namenode
- master

- slave1

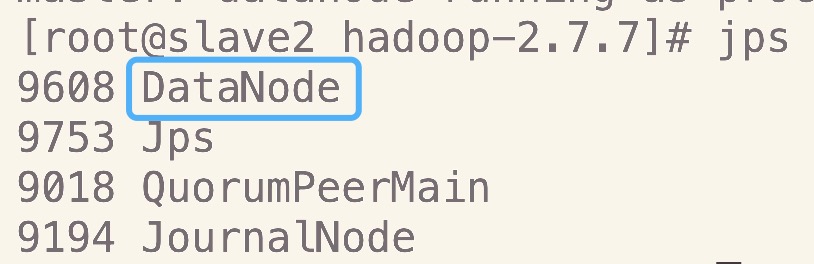
6.启动启动datanode
在master上执行如下命令
hadoop-daemons.sh start datanode
- master

- slave1
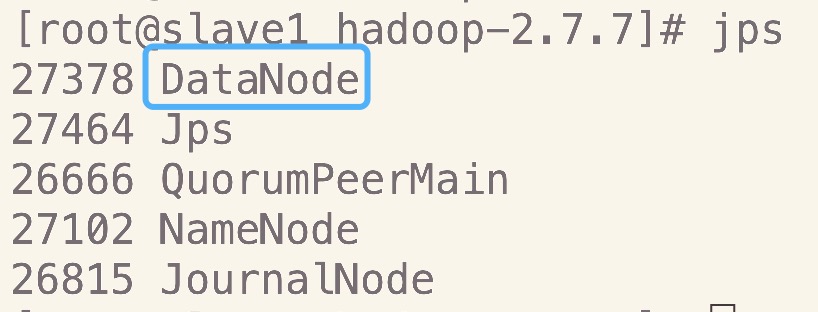
- slave2
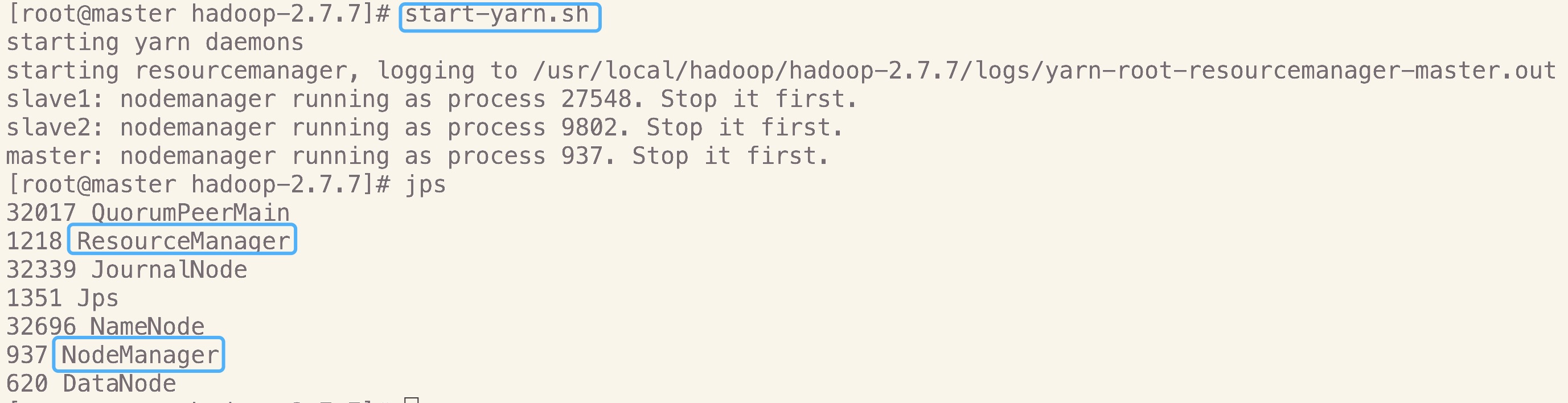
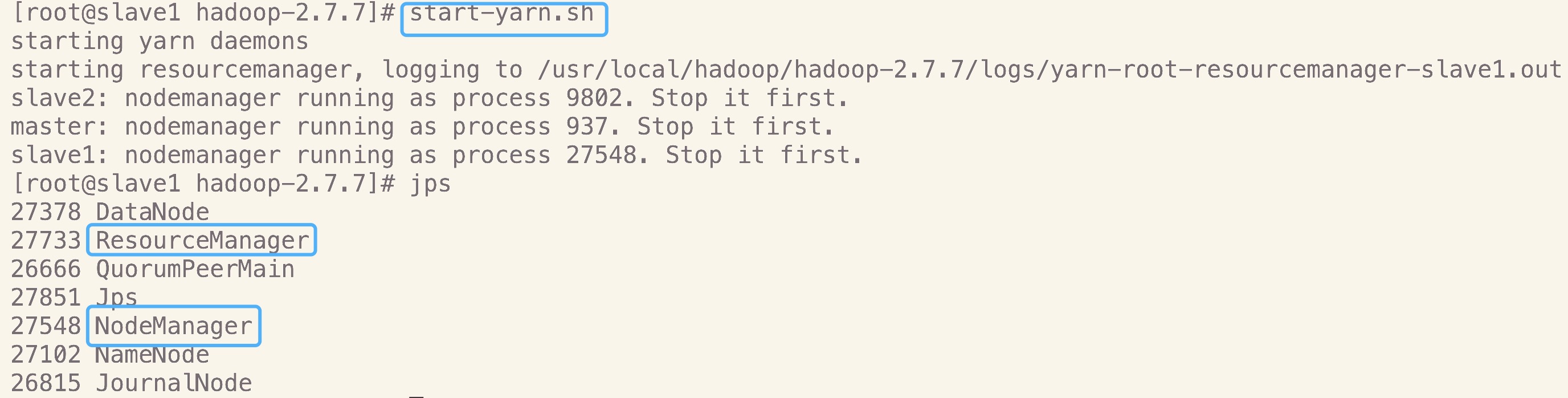
7.启动yarn
在作为资源管理器上的机器上启动,我这里是master和slave1,执行如下命令完成yarn的启动
start-yarn.sh
- master
- slave1
8.启动ZKFC
在master上执行如下命令,完成ZKFC的启动
hadoop-daemons.sh start zkfc
- master
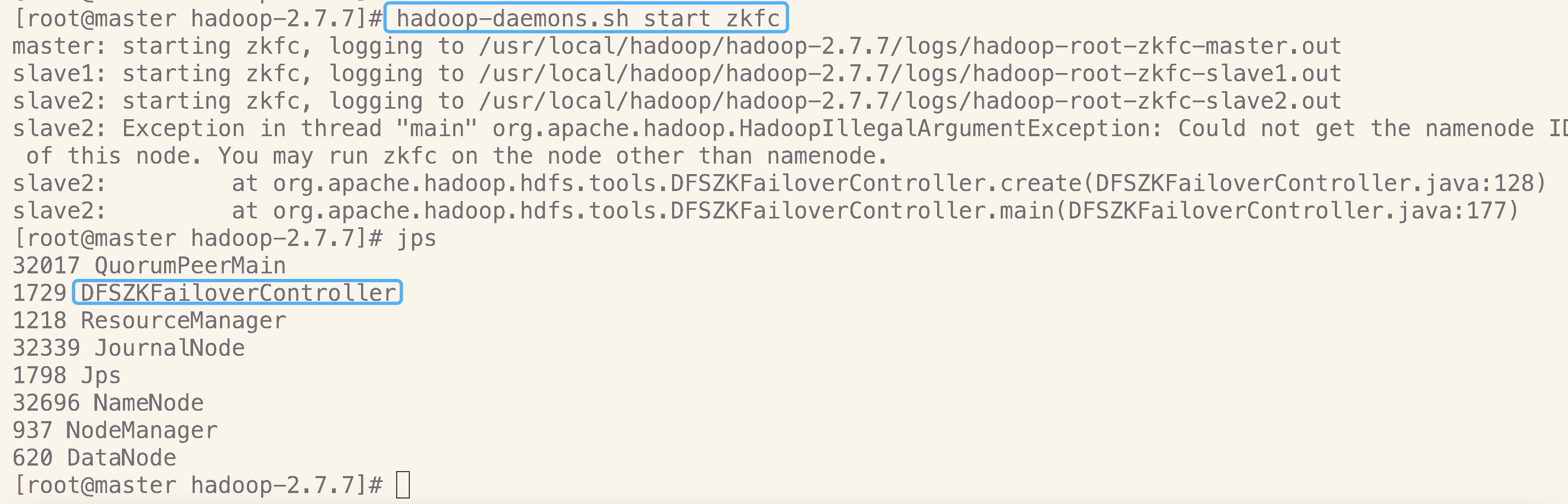
因为slave2没有namenode所以不需要zkfc
- slev1
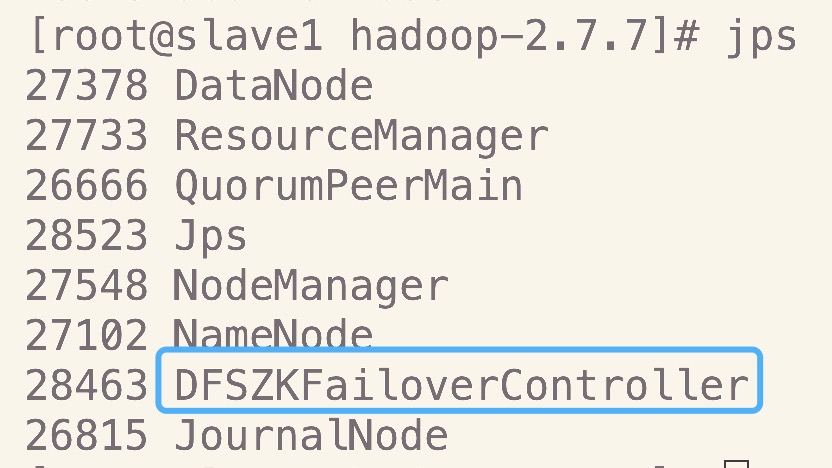
9.jps查看全部进程
全部启动完后分别在各节点上执行jps是可以看到下面这些进程
- master
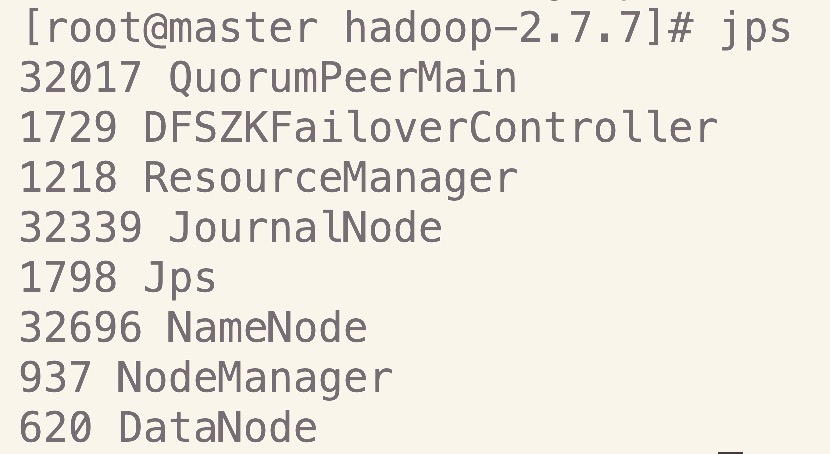
- slave1

- slave2

六、测试HA的高可用性
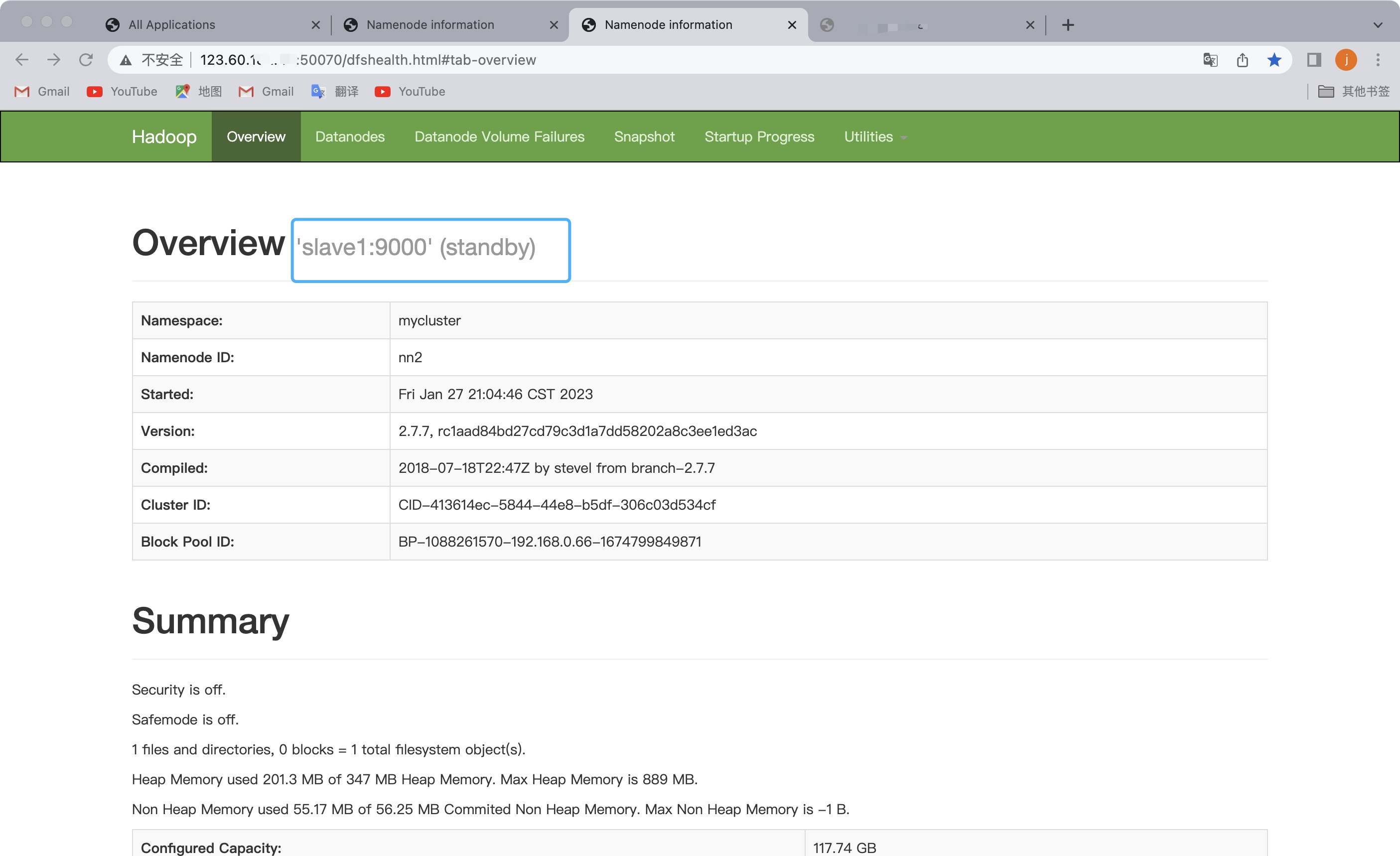
- 启动后maste的namenode和slave1的namenode如下所示:
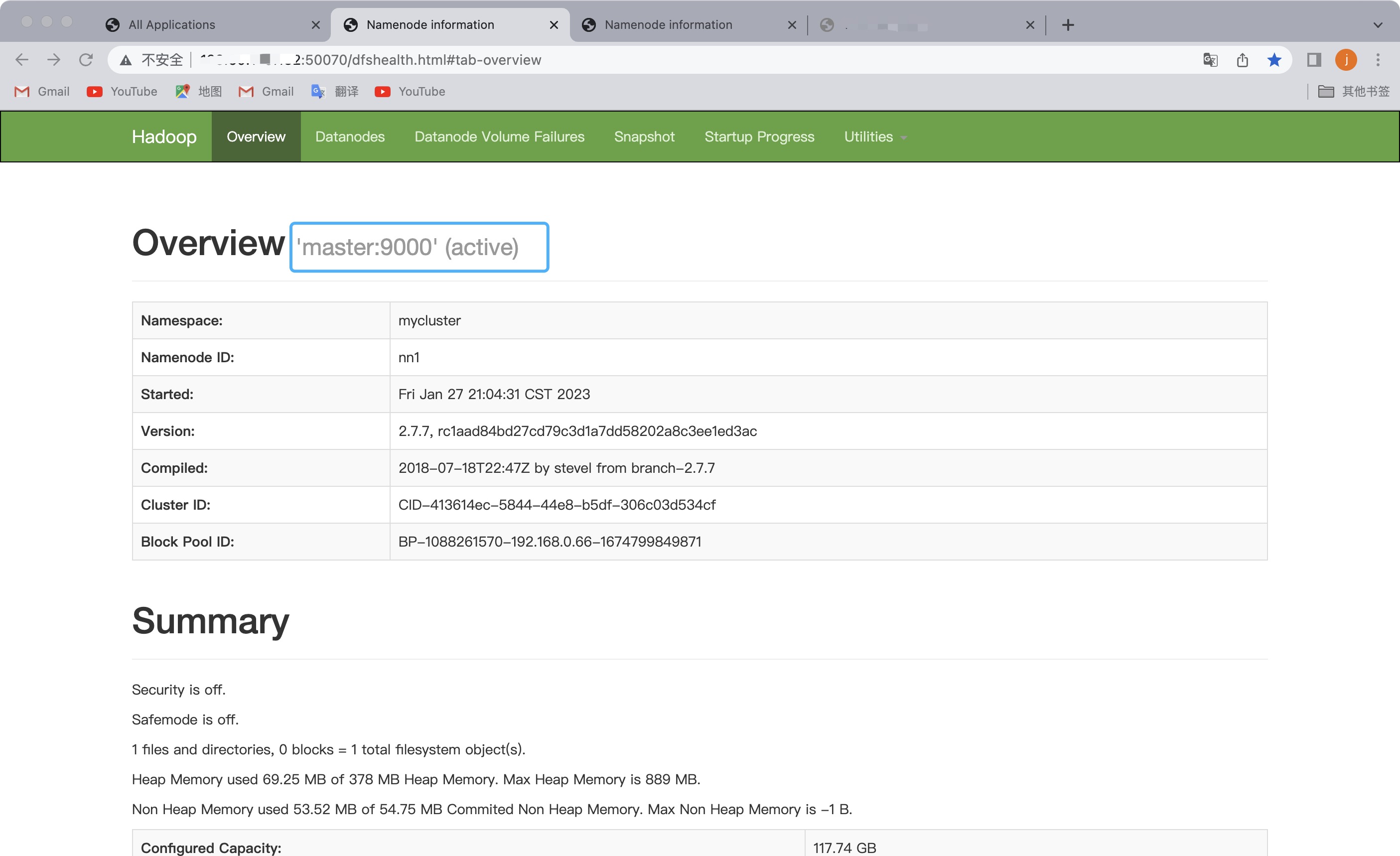
- web端访问yarn
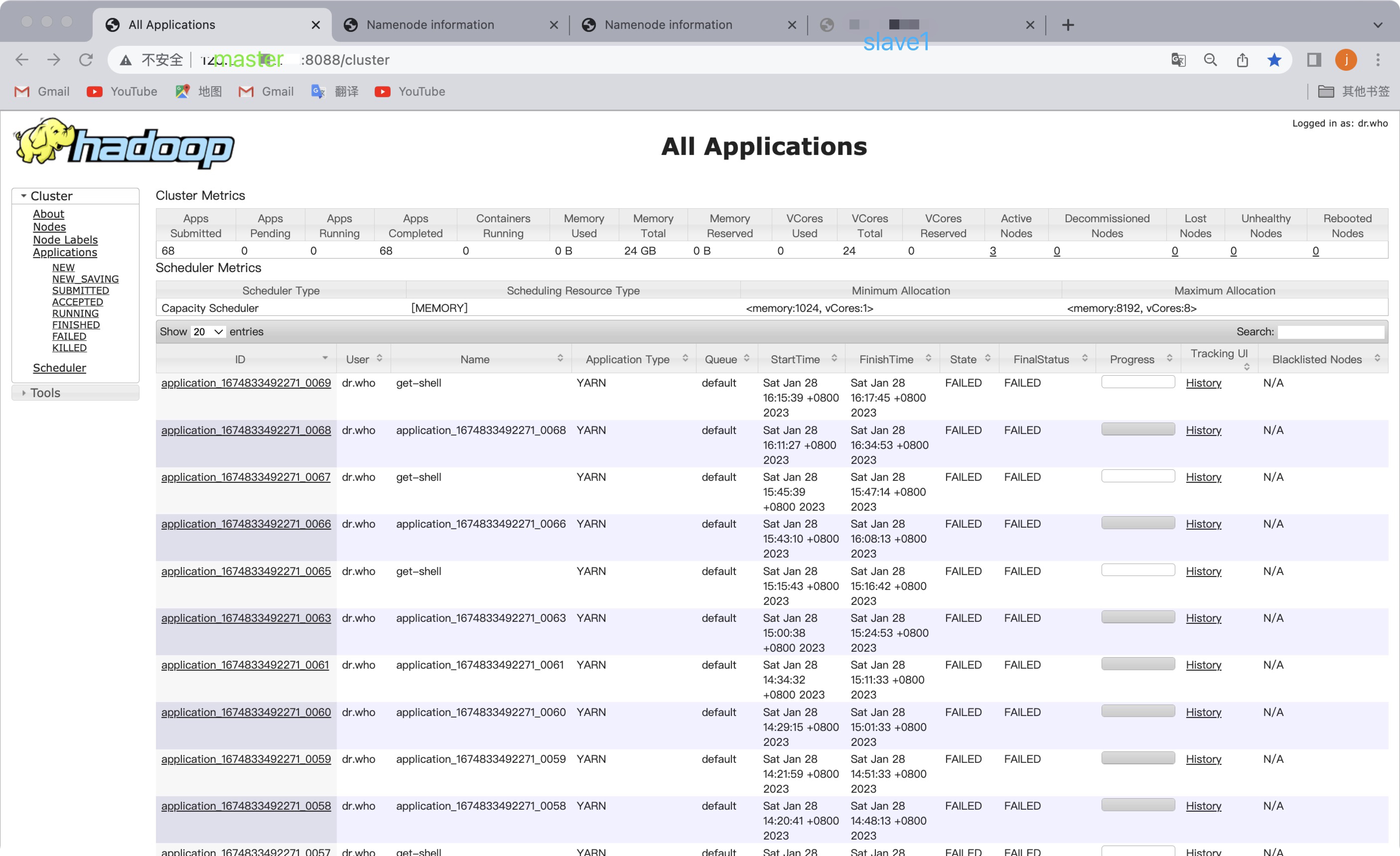
⚠️此刻master主机是主节点,访问slave1的yarn会自动跳转到主节点上,IP会变成master(高可用 一主一从)
此时,我们停掉master主机上的namenode
在master上执行命令hadoop-daemon.sh stop namenode此时slave1上的namenode变为active状态
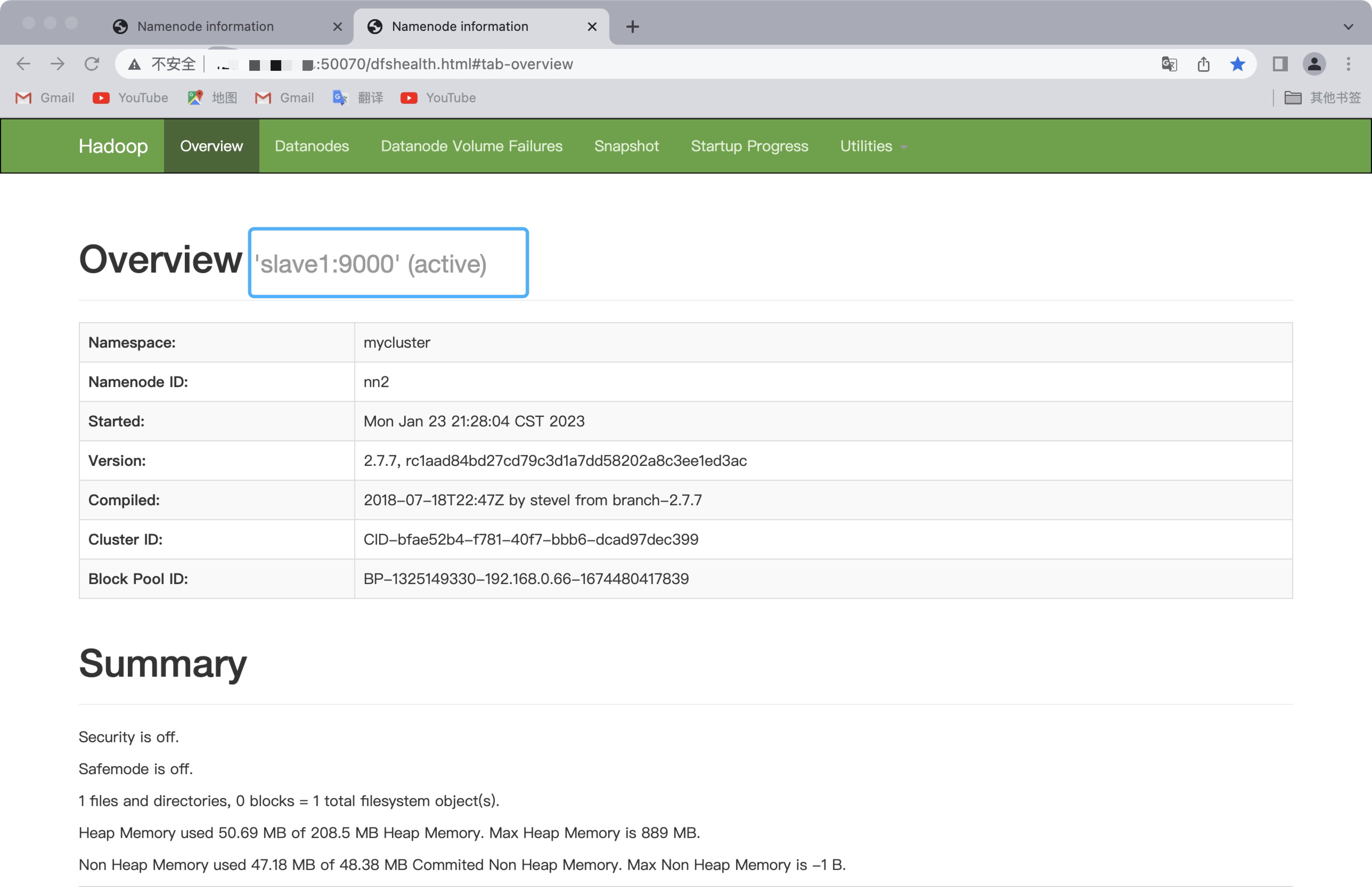
再启动maste上的namenode,在命令行输入:
hadoop-daemon.sh start namenode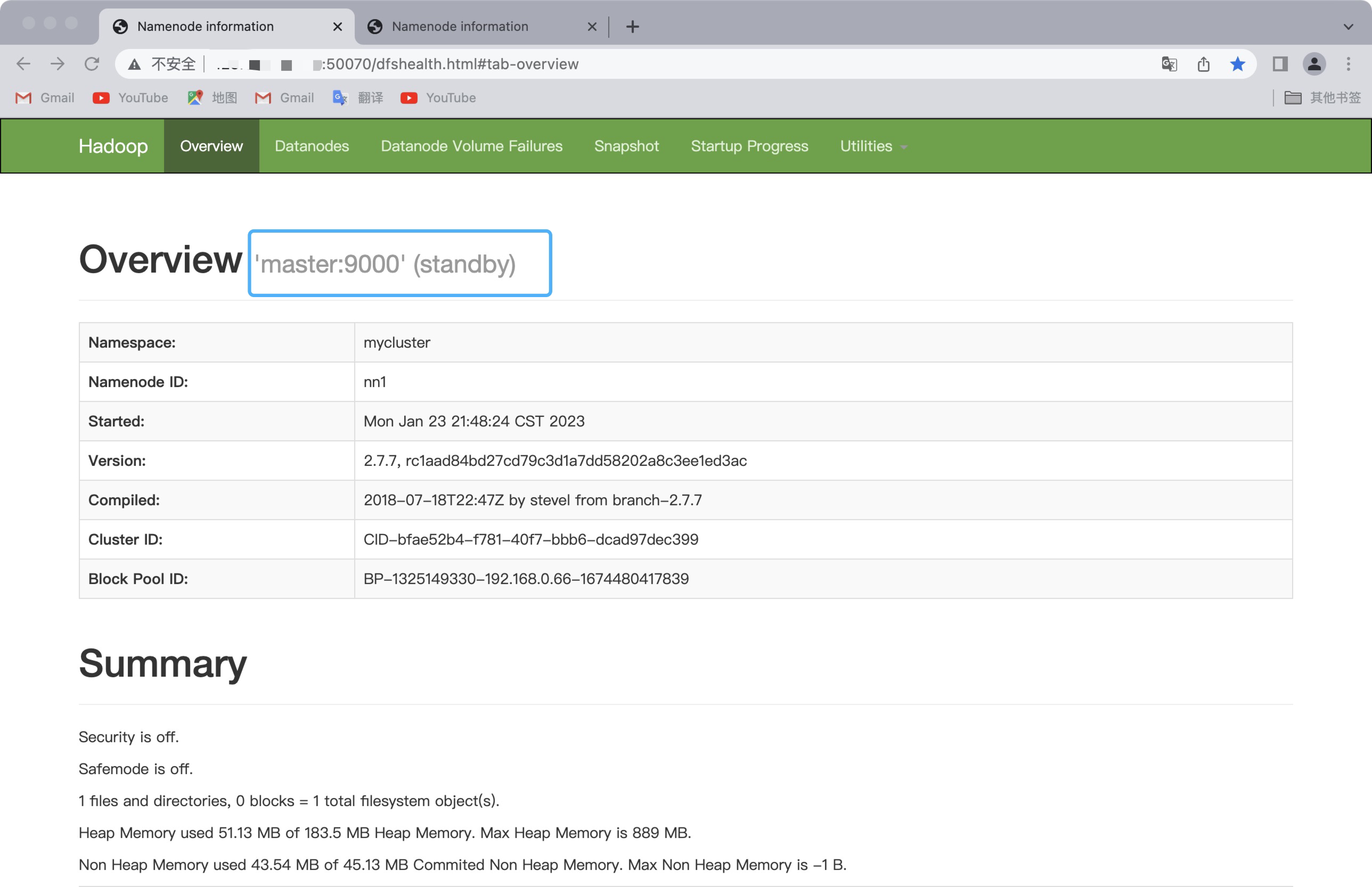
yarn的web页面同理,slave1变成主节点,访问master会跳到slave1
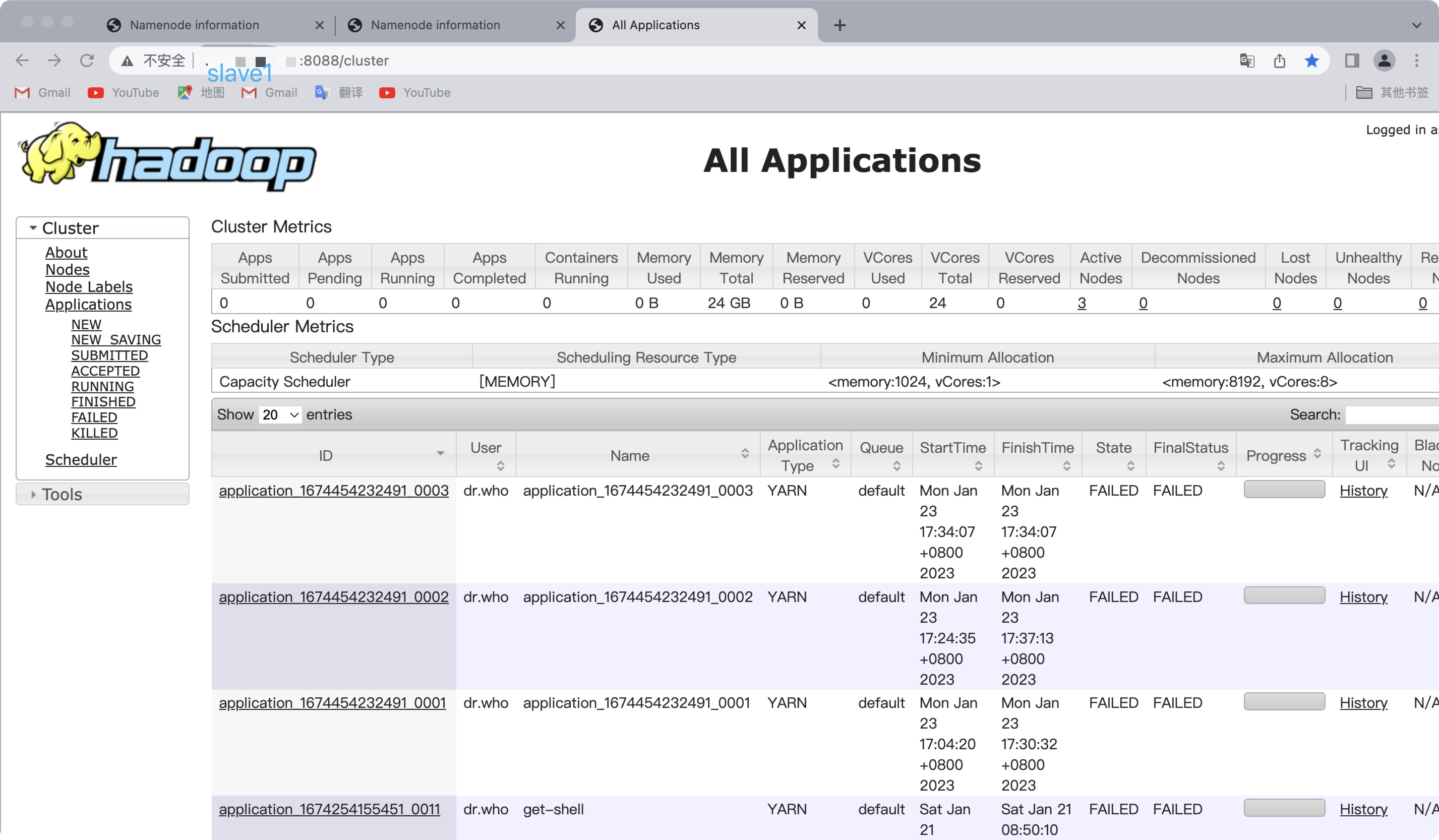
🌱小结:如果master上的namenode挂掉,它的namenode就会变为由active状态变成standby状态,而slave1的namenode即由standby状态变成active状态,实现了namenode的高可用,yarn同理~
到这里基于zookeeper的 Hadoop HA集群就搭建完成啦🌿
七、几个重要端口
- 对于jps不显示的情况,很有可能那个端口被占用了
- 查看日志,如果和下图一样

可以查看端口,kill掉进程,再重新启动,jps一下
- JournalNode(8480)
hadoop-daemon.sh start journalnode
lsof -i:8480
- DataNode(50010)
hadoop-daemons.sh start datanode
lsof -i:50010
- ResourceManager(8088)
- NodeManager(8040)
start-yarn.sh
lsof -i:8088
lsof -i:8040
- DFSZKFailoverController(8019)
- QuorumPeerMain(3888)
hadoop-daemons.sh start zkfc
lsof -i:8019
lsof -i:3888
🌱Hadoop HA搭建过程比较烦琐,遇到问题可以多看看log日志,同时需要注意操作的前后顺序噢,祝你成功!
参考资料
Hadoop之——Hadoop2.5.2 HA高可靠性集群搭建(Hadoop+Zookeeper)
—— 本文完 · 感谢读到这里的你 🐾 ——