
摘要: 本文主要记录📝基于Hadoop环境的Hive(2.3.4)的安装与配置(使用mysql作为元数据库),以及补充学到的知识点,文章以图文形式呈现,主要参考CSDN博主「原来浙小商啊」。
背景
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。Hive构建在 Apache Hadoop之上,支持通过 hdfs 在 S3、adls、gs 等上进行存储。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
一、环境准备
- 三台服务器(master、slave1、slave2)
- 各节点完成了IP映射与ssh免密
没完成的可以看下这篇文章《云服务器IP映射与ssh免密登录》 - Hadoop集群完成配置
没完成的可以看下这篇文章《Hadoop完全分布式配置》 - 相关软件安装包下载
百度云链接 提取码:r93h
由CSDN博主「原来浙小商啊」提供
二、Hive的基本安装
1.hive下载和解压
你可以直接使用和我对应版本我软件包,也可以去hive的官网下载
上传⏫文件可以用scp,前面文章有写
⚠️Hive只需要在master节点上安装配置
- 进入/usr/local目录,解压apache-hive-2.3.4-bin.tar.gz 到该目录下,并将解压的文件重命名为hive-2.3.4,最后移动到创建的hive文件夹中
1 | [root@master ~]# cd /usr/local |
可以切换到hive目录下查看解压好的文件夹
2.配置hive环境变量
- 设置环境变量,编辑vi /etc/profile,在末尾添加以下代码;
1 | [root@master hive]# vim /etc/profile |
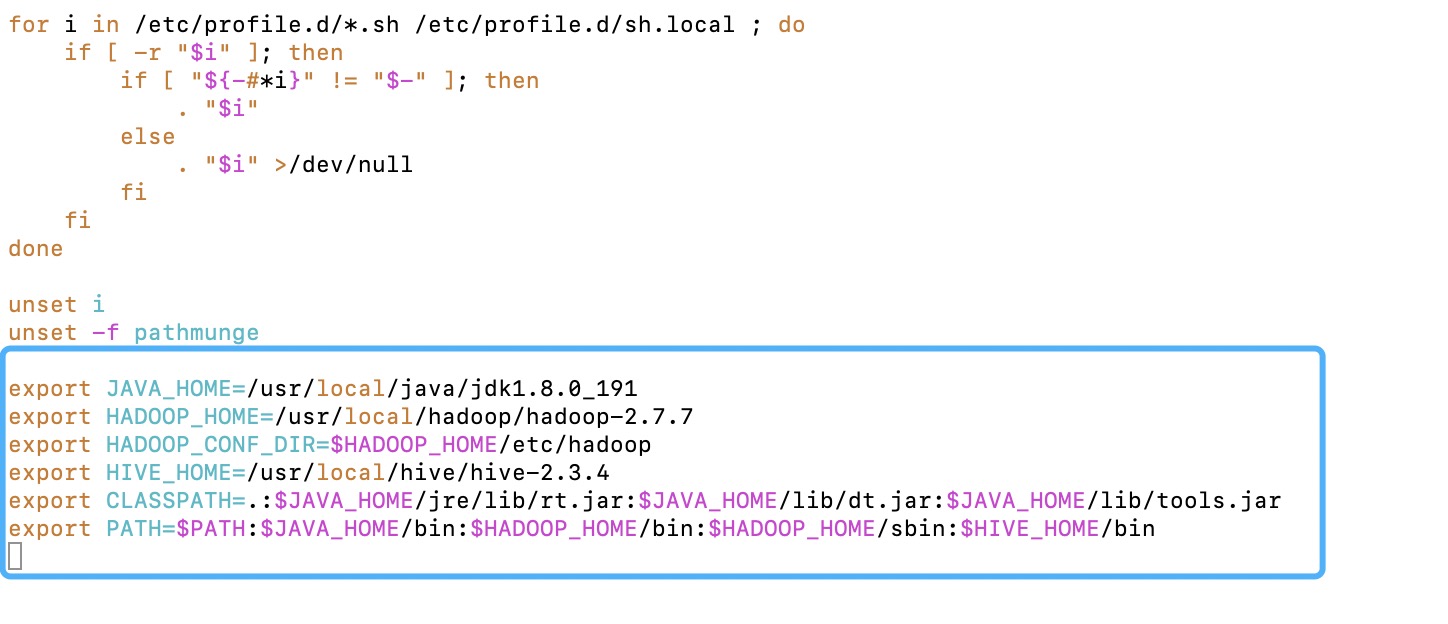
最后:source /etc/profile使刚刚的配置生效[root@master ~]# source /etc/profile
- 查看hive是否安装成功:
[root@master ~]# hive --version
出现如下界面代表配置成功

出现hive版本就说明安装成功
三、Hive的配置
- 在/usr/local/hive/hive-2.3.4/conf目录下,修改hive-site.xml和hive-env.sh两个文件
1.hive-site.xml
- hive-site.xml保存Hive运行时所需要的相关配置信息。
1 | [root@master hive]# cd hive-2.3.4/conf |
- 温馨提示:文件有5千多行,如果你和我版本对应可以直接用软件包里的这个文件,要修改的话,可以将这个文件下载到自己主机用编辑器编辑后再上传
我是直接把master上的hive-site.xml删了,直接创建一个:vi hive-site.xml,将软件包里hive-site.xml的文件内容全选复制到其中(按i进入编辑模式后再进行粘贴)
- 自己编辑如下:
⚠️在hive-site.xml中找到下面的几个对应name的property,然后把value值更改
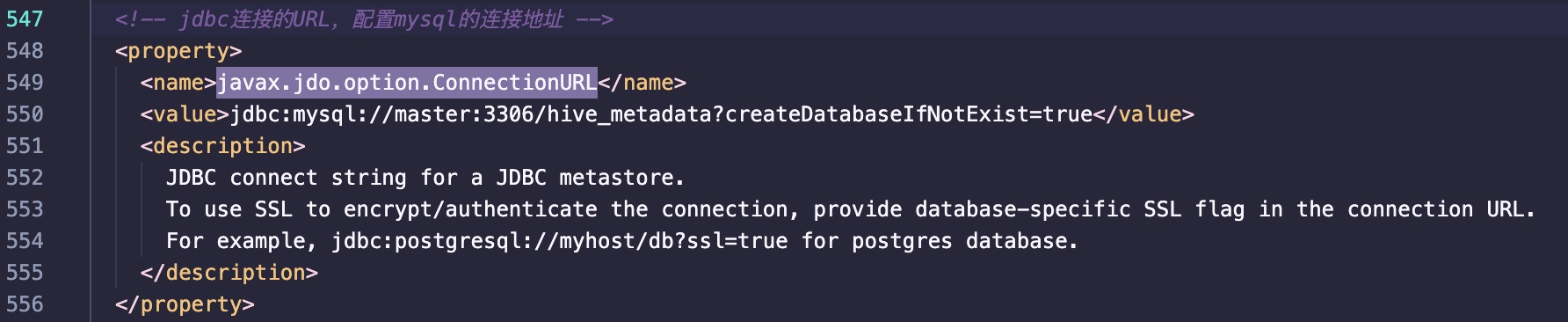
- javax.jdo.option.ConnectionURL
1 | <property> |
- javax.jdo.option.ConnectionDriverName
1 | <property> |

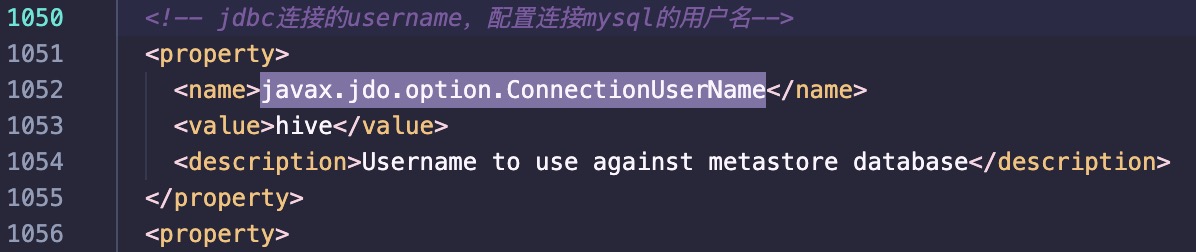
- javax.jdo.option.ConnectionUserName
1 | <property> |
- javax.jdo.option.ConnectionPassword
1 | <property> |

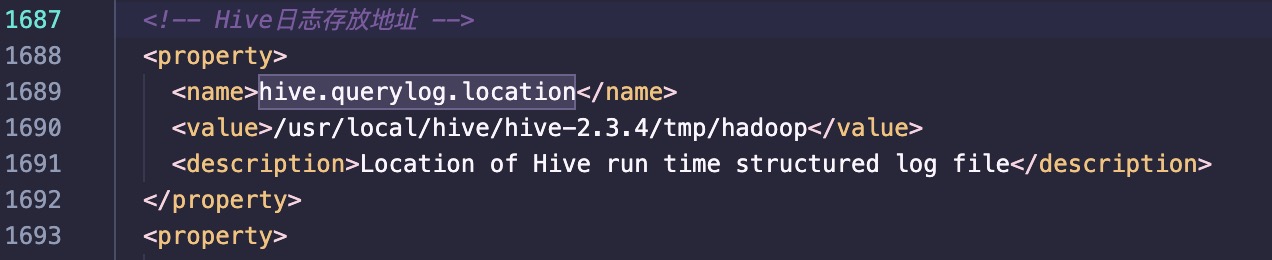
- hive.querylog.location
1 | <property> |
- hive.server2.logging.operation.log.location
1 | <property> |

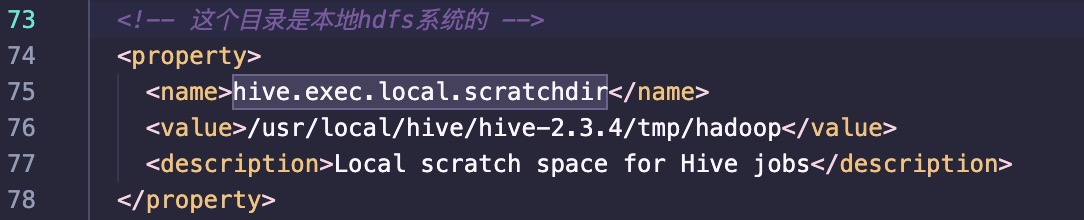
- hive.exec.local.scratchdir
1 | <property> |
- hive.downloaded.resources.dir
1 | <property> |

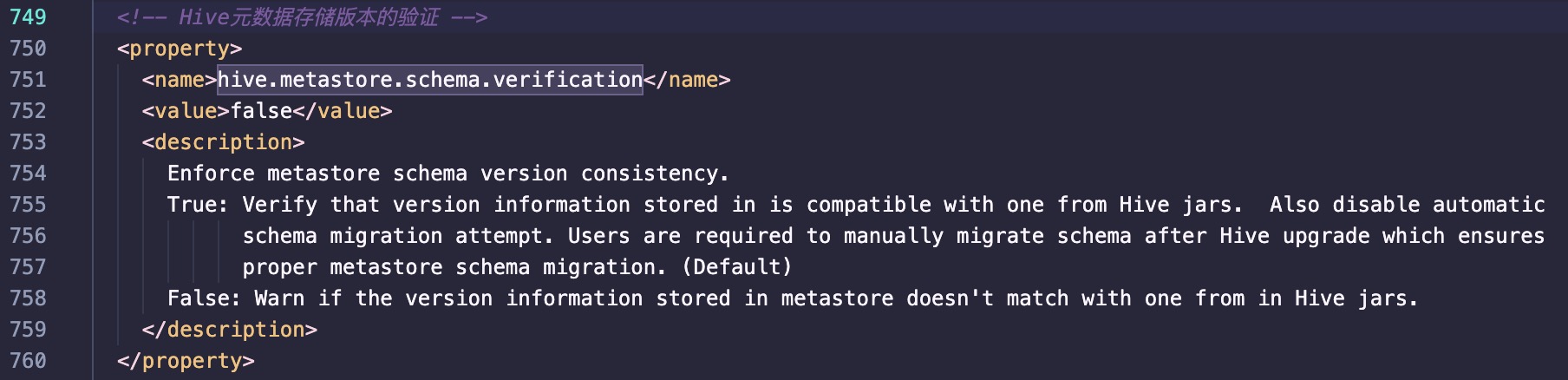
- hive.metastore.schema.verification
1 | <property> |
完成后,记得保存哦,一定要细心🌱
2.hive-env.sh
- 由于Hive是一个基于Hadoop分布式文件系统的数据仓库架构,主要运行在Hadoop分布式环境下,因此,需要在文件hive-env.sh中指定Hadoop相关配置文件的路径,用于Hive访问HDFS(读取fs.defaultFS属性值)和MapReduce(读取mapreduce.jobhistory.address属性值)等Hadoop 相关组件。
[root@master conf]# mv hive-env.sh.template hive-env.sh
- vi hive-env.sh打开文件,找到下面的位置,做对应修改
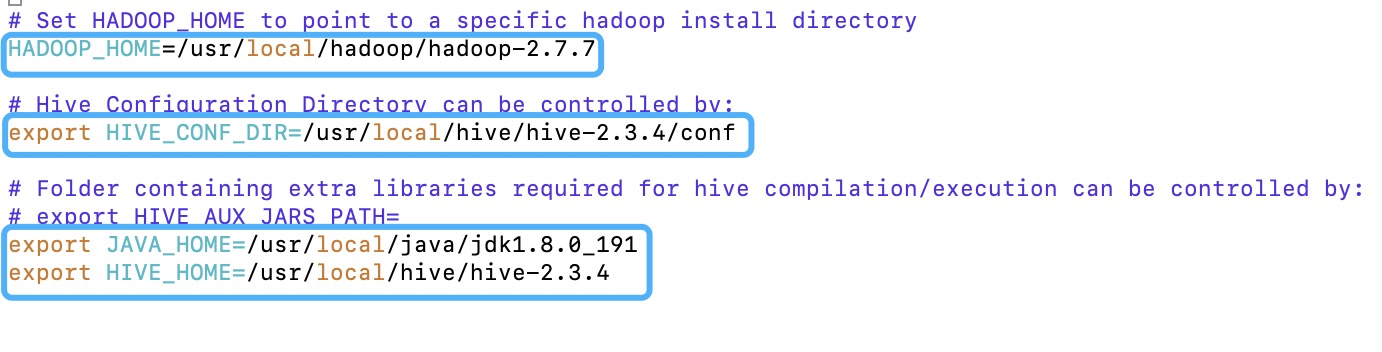
1 | HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7 |
至此Hive基础配置完成啦🌿
四、Mysql的安装与配置
Hive需要数据库来存储metastore的内容,因此我们需要配置一下MySQL数据库。
1.MySQL下载
- 下载mysql驱动
把下载好的mysql-connector-java.jar这个jar包拷到/usr/local/hive/hive-2.3.4/lib/下面,在百度云链接 (提取码:r93h)里都有
- 安装MySQL数据库
1 | [root@master ~]# cd /usr/local/src/ |
出现如下界面代表安装成功
安装完成后,重启服务
[root@master src]# service mysqld restart
mysql安装成功
2.MySQL为Hive做的设置
⚠️mysql用户和密码已经在hive-site.xml文件设置好了哦,这里就不需要重复了
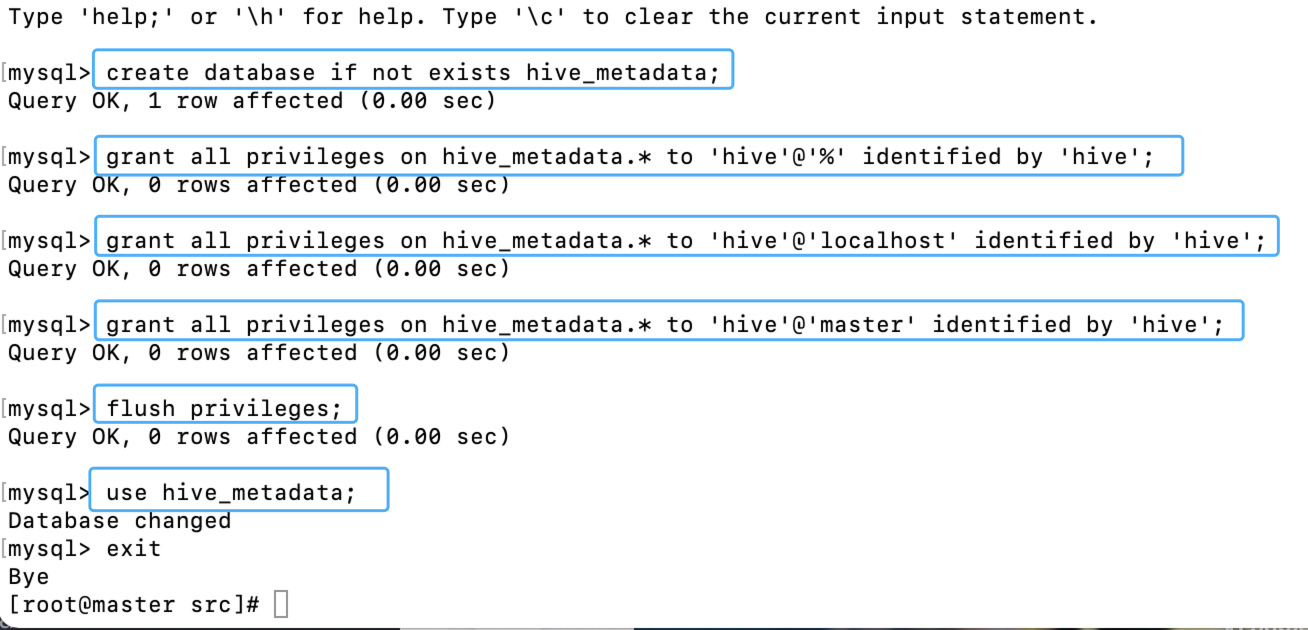
- 在mysql上创建hive元数据库hive_metadata
create database if not exists hive_metadata;
- 创建用户hive,密码为hive,并授权拥有数据库实例hive_metadata的所有权限
grant all privileges on hive_metadata.* to 'hive'@'%' identified by 'hive';
- 对hive元数据库进行赋权,开放localhost连接,开放远程连接
grant all privileges on hive_metadata.* to 'hive'@'localhost' identified by 'hive';
grant all privileges on hive_metadata.* to 'hive'@'master' identified by 'hive';
- 刷新系统权限表。
flush privileges;
- 使用实例hive_metadata
use hive_metadata;
五、Hive初始化及测试hive
1.初始化
⚠️完成Hive的安装与配置后,确保Hadoop的dfs在运行哦(start-dfs.sh启动 Hadoop),jps先验证一下
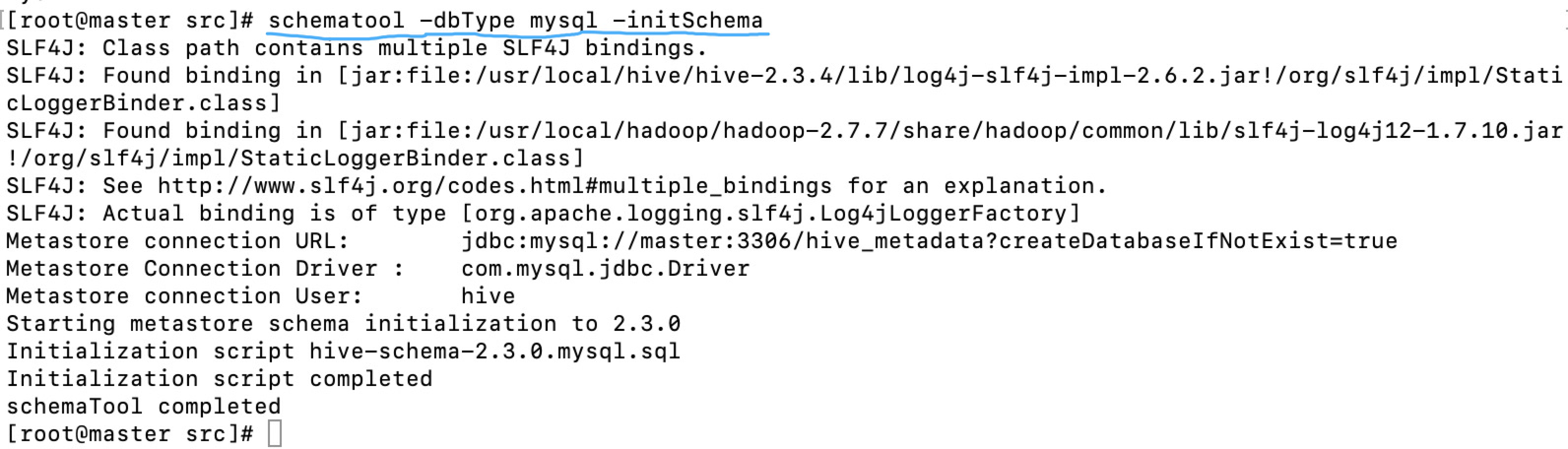
第一次启动Hive前还需要执行初始化命令[root@master src]# schematool -dbType mysql -initSchema
在主机上输入http://虚拟机ip地址:50070/ 可以访问 hadoop的管理页面
如果文件hdfs权限不够的输入如下命令:hdfs dfs -chmod -R 777 /tmp
hive在hdfs创建了两个目录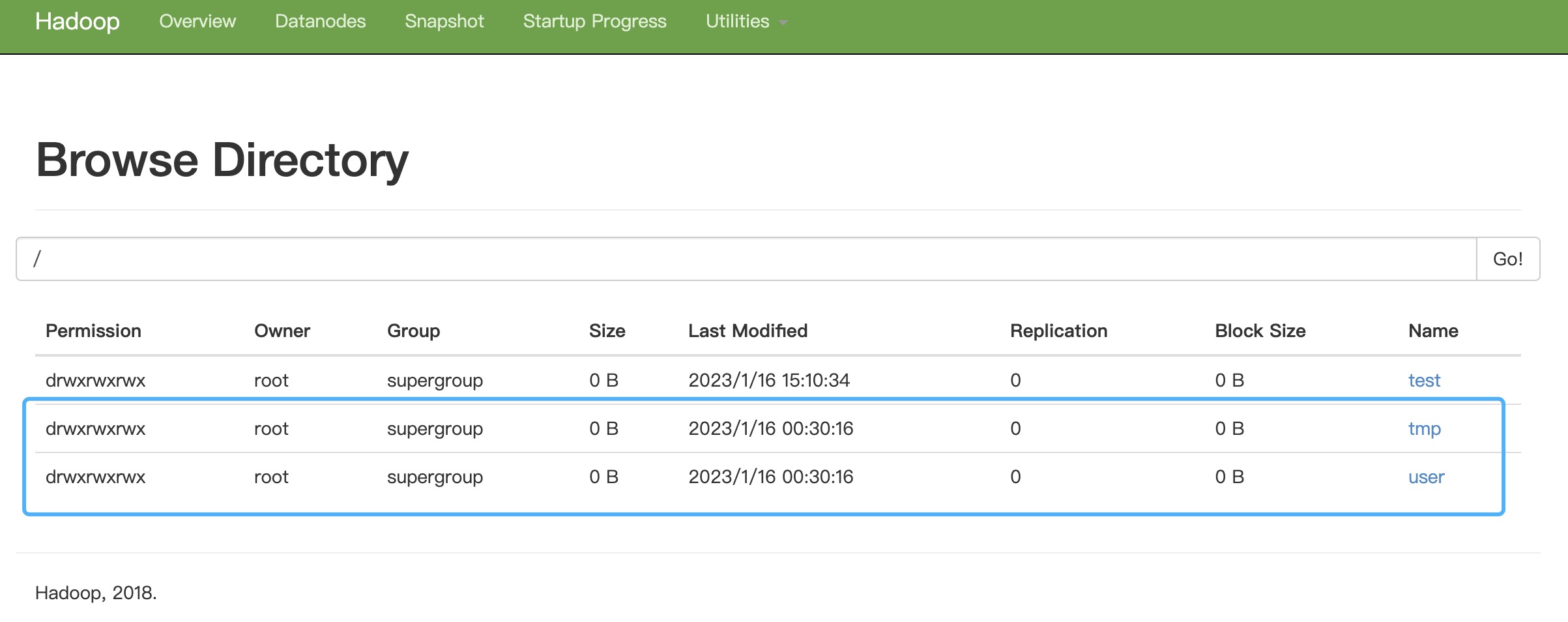
2.测试hive
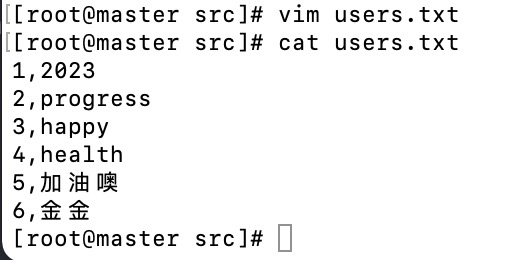
- 先创建一个txt文件存点数据等下导入hive中去
[root@master src]# vim users.txt
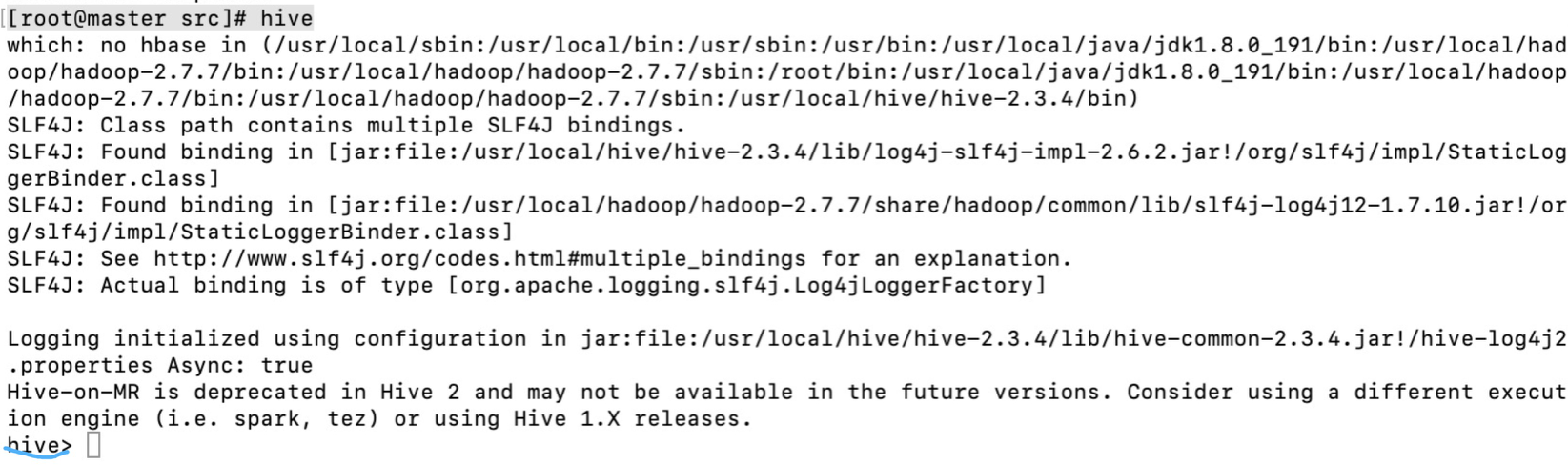
- 进入hive,出现命令行就说明之前搭建是成功的
- 创建users表,因为我们上面users.txt不同字段中间有逗号所以
这个row format delimited fields terminated by ‘,’代表我们等下导过来的文件中字段是以逗号“,”分割字段的
hive> create table users(id int, name string) row format delimited fields terminated by ',';
- 导数据
hive> load data local inpath '/usr/local/src/users.txt' into table users;
- 查询
hive> select * from users;
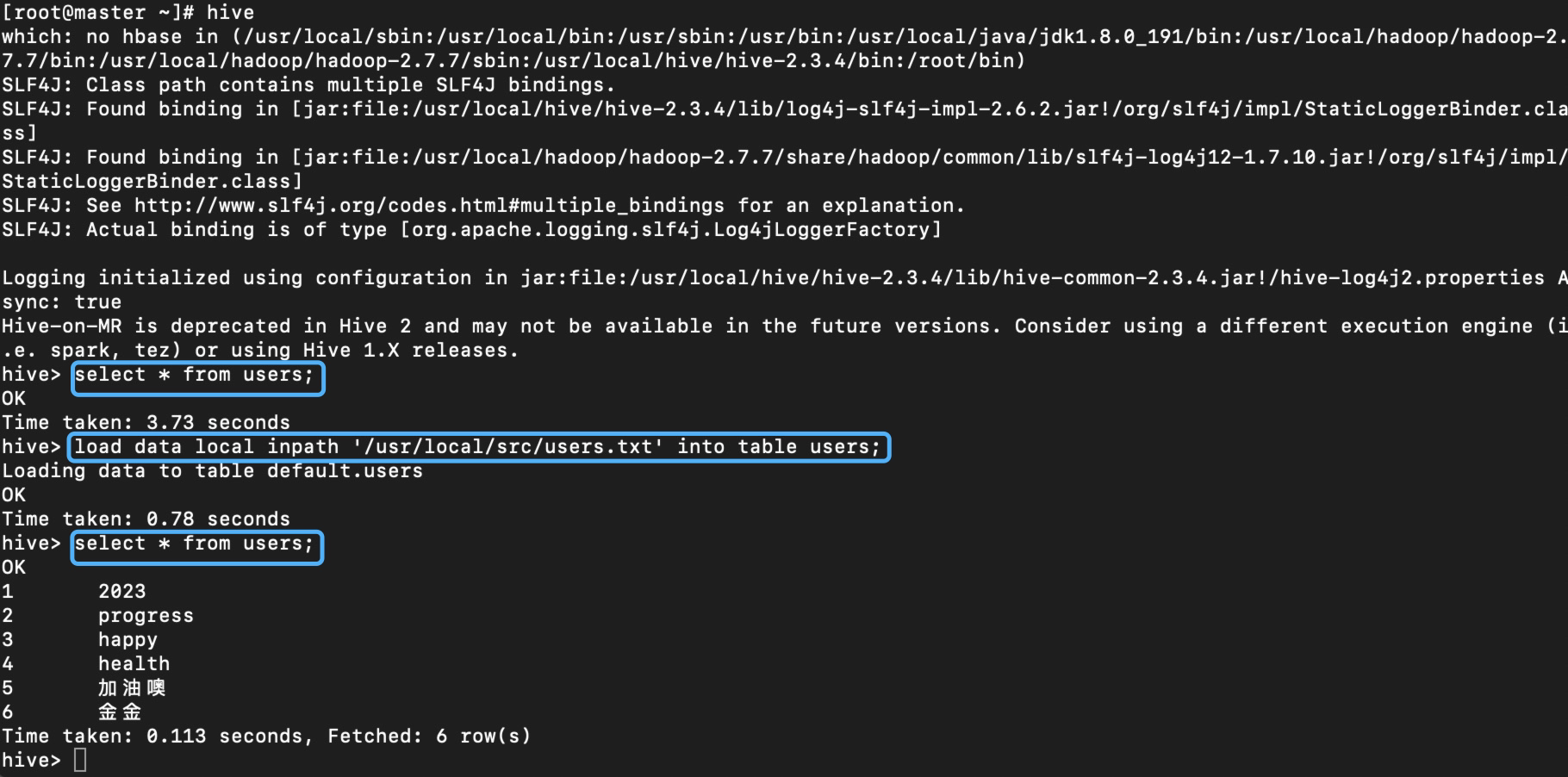
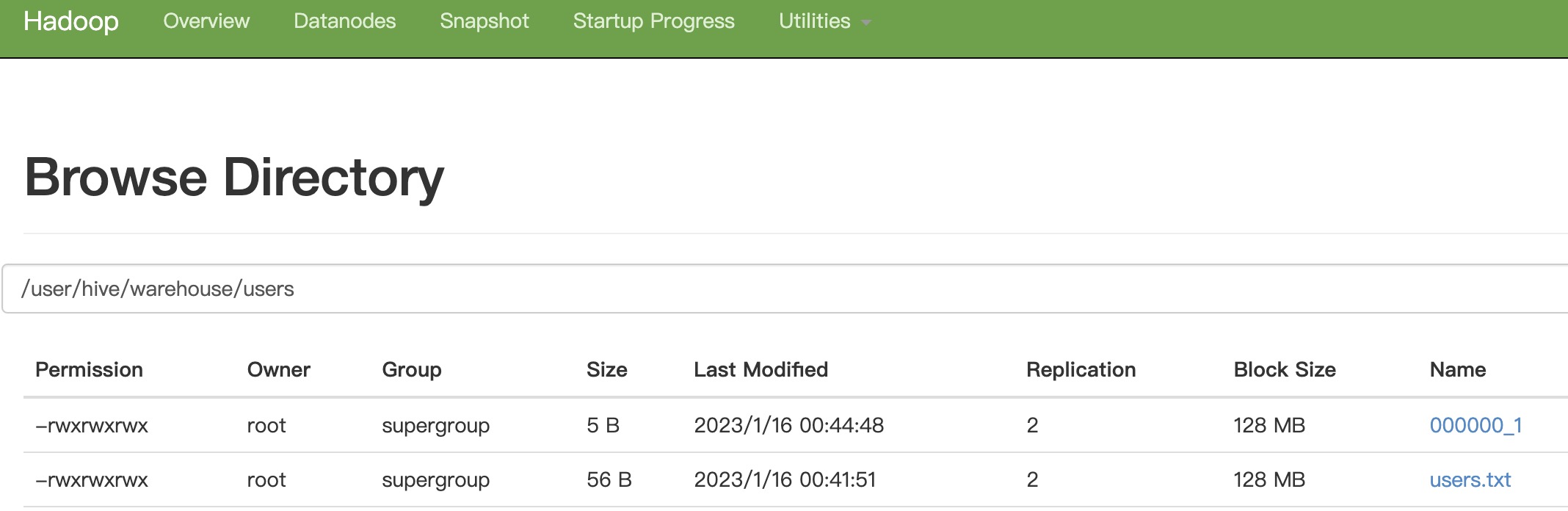
🍃到此为止,hive配置就结束啦,祝你成功!
—— 本文完 · 感谢读到这里的你 🐾 ——