
摘要: 本文主要记录📝搭建一个Namenode两个DataNode的Hadoop完全分布式集群(Hadoop2.7.7)的全部步骤和HDFS系统初体验,以及补充学到的知识点,文章以图文形式呈现,主要参考CSDN博主「原来浙小商啊」。
背景:
目前得到广泛应用的大数据平台就是Hadoop了,Hadoop开源项目已经成为研究大数据,开发大数据应用的重要平台,在我国已经形成了一个庞大的社群。Hadoop自2006年面世,经过十多年的技术迭代,其技术生态圈也日益壮大,从最初只有HDFS和MapReduce两个组件,发展到当前的六十多个组件,覆盖了从数据存储,执行引擎到数据访问框架等各个层面,在提供了前所未有的计算能力的同时,也大大降低了计算成本,使其在大规模数据处理分析上的表现远远超过其他产品,不但被广泛应用于各行各业的数据分析和处理,更已经成为各大企业数据平台的首选。
一、环境准备
- 三台服务器(master、slave1、slave2)
- 各节点完成了IP映射与ssh免密
没完成的可以看下这篇文章《云服务器IP映射与ssh免密登录》 - 相关软件安装包下载
百度云链接 提取码:r93h
由CSDN博主「原来浙小商啊」提供
二、安装 Java
Hadoop是基于Java开发的,所以部署Hadoop之前需要在Linux系统中配置Java的开发环境。
你可以直接使用和我对应版本我软件包,也可以去O\fracle的官网下载JDK
- 上传文件
- 配置Java环境变量
- 测试
1.上传文件
可以先下载到本地,然后从本地中将文件传入到虚拟机中。
也可以复制链接地址,在Linux系统中下载,不过复制链接地址不能直接下载,因为O\fracle做了限制,地址后缀需要加上它随机生成的随机码,才能下载到资源。
scp (你的本地文件路径) (上传的云服务器名称):(存放路径)
例如我的:
1 | scp Desktop/jdk-8u191-linux-x64.tar.gz root@123.60.179.1:/usr/local/ |
我们之后所有环境配置包都放到/usr/local/下
1 | [root@master ~]# cd /usr/local |
2.配置Java环境变量
解压好JDK之后还需要在环境变量中配置JDK,才可以使用
在profile文件末尾添加Java的环境变量(不可以有空格):
1 | [root@master ~]# vim /etc/profile |
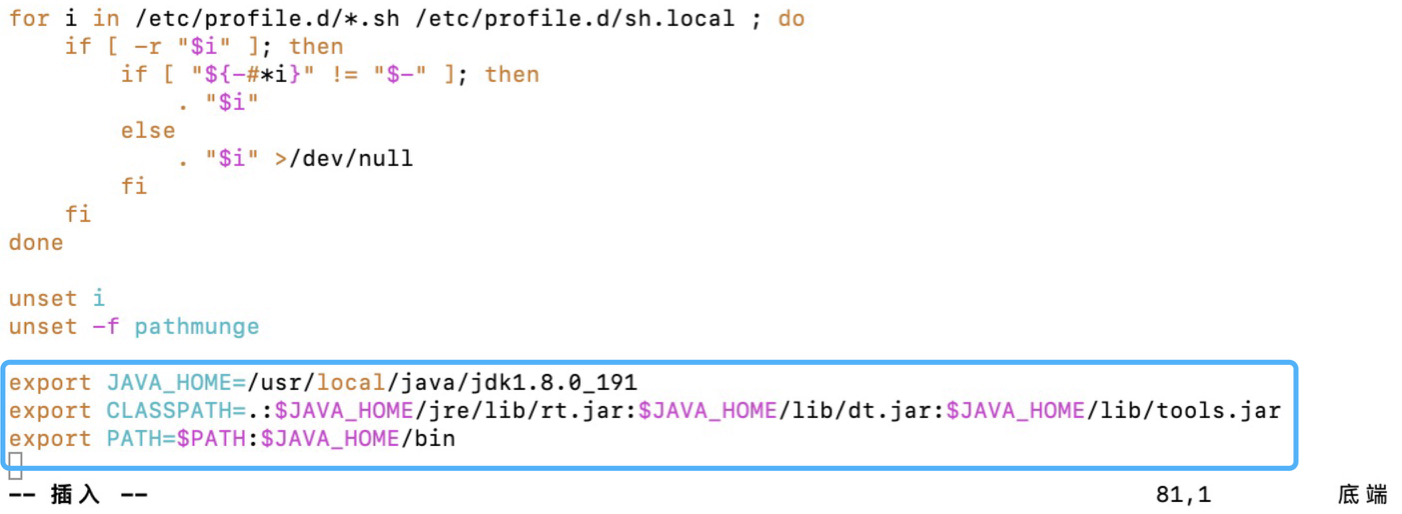
最后:source /etc/profile使刚刚的配置生效
1 | [root@master ~]# source /etc/profile |
3.测试
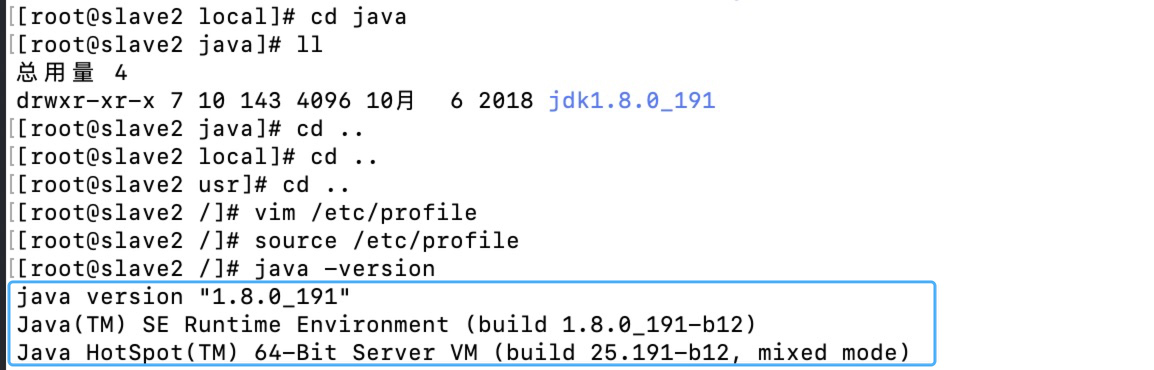
[root@master ~]# java -version
输入:java -version 出现如下界面代表配置成功。
其他两个节点同样操作
因为配置总是要修改profile文件,三个节点的profile差不多(除了后面hive只用在主节点配置),所以我每次都把其他两个节点的这个文件删了,在scp,把配置好的文件传过去
1 | scp -r profile slave1:/etc/ |
⚠️ master传文件,要在那个文件目录下传,例如传profile文件要在/etc/目录下
传完之后记得
1 | [root@master ~]# source /etc/profile |
一定要确认三个节点都安装好了Java
三、Hadoop安装与配置
- 安装Hadoop
- Hadoop完全分布式配置
1.安装Hadoop
官网下载
也可直接用文中软件包
下载解压
在/usr/local下创建hadoop文件夹,将下载好的hadoop-2.7.7压缩包上传进去解压
1 | [root@master ~]# cd /usr/local |
可以切换到hadoop目录下查看解压好的文件夹
- Hadoop的重要目录结构的了解
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例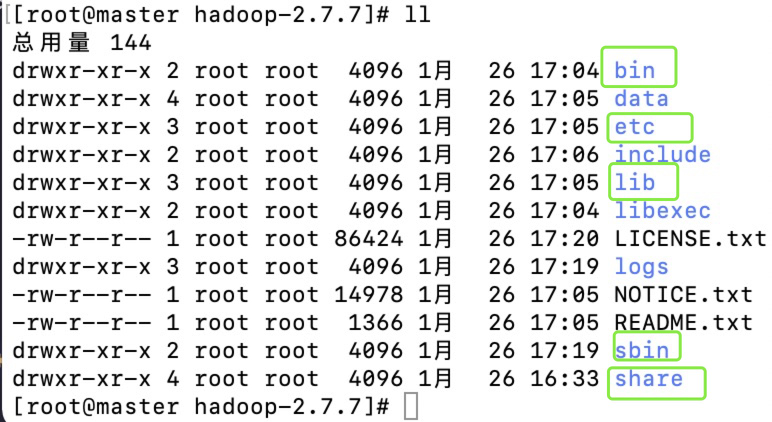
2.Hadoop完全分布式配置
- 将Hadoop添加到环境变量中
1 | [root@master hadoop]# vim /etc/profile |
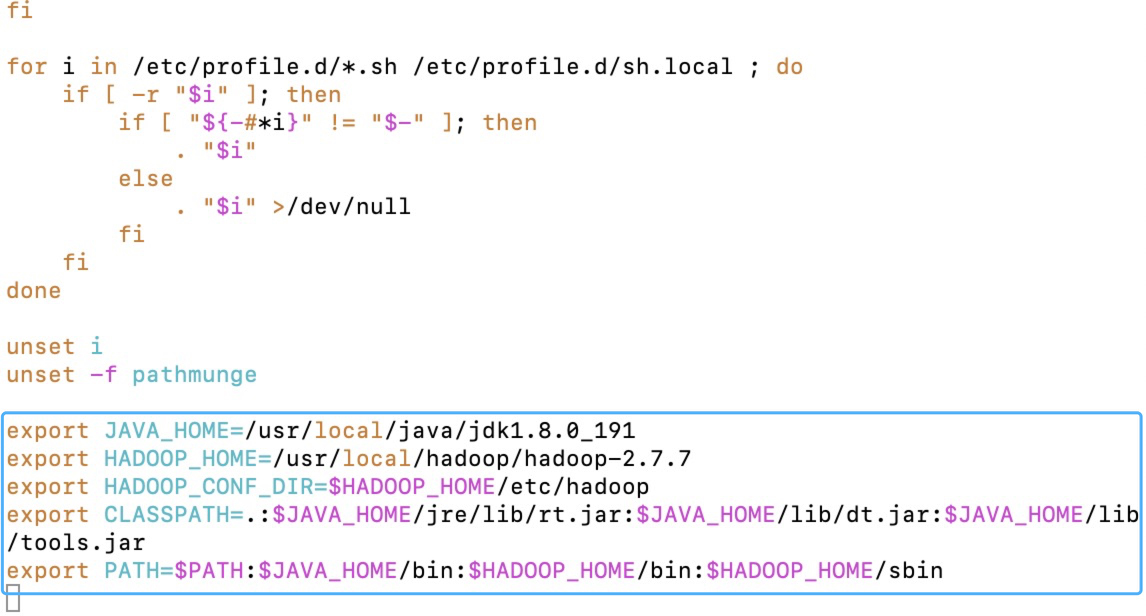
最后:source /etc/profile使刚刚的配置生效[root@master ~]# source /etc/profile
- 测试
[root@master ~]# Hadoop version
出现如下界面代表配置成功。

- 了解配置文件
hadoop的默认配置文件
core-default.xml
hdfs-default.xml
mapread-default.xml
yarn-default.xml
⚠️配置集群的相关信息(修改hadoop自定义的配置文件)
hadoop提供可自定义的配置文件
| 配置文件 | 功能描述 |
|---|---|
| core-site.xml | Hadoop核心全局配置文件,可在其他配置文件中引用该文件 |
| hdfs-site.xml | HDFS配置文件,继承core-site.xml配置文件 |
| mapred-site.xml | MapReduce配置文件,继承core-site.xml配置文件 |
| yarn-site.xml | YARN配置文件,继承core-site.xml配置文件 |
| hadoop-env.sh | 配置Hadoop运行所需要的环境变量(主要映射jdk的环境变量) |
| slaves | 用于记录集群所有的从节点的主机名,包括HDFS的DataNode节点和YARN的NodeManager节点 |
- 集群规划
| master | slave1 | slave2 | |
|---|---|---|---|
| HDFS | NameNode、SecondaryNameNode | DataNode | DataNode |
| YARN | ResourceManager | NodeManager | NodeManager |
- 配置文件
好了准备工作已经做完了,我们要开始修改Hadoop的配置文件,
总共需要修改6个文件。
配置文件主要在hadoop-2.7.7/etc/hadoop下面
分别是:
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- slaves
- hadoop-env.sh
我们一个一个接着来配置吧!
1 | [root@master hadoop]# cd hadoop-2.7.7/etc/hadoop |
1.core-site.xml
这个是核心配置文件我们需要在该文件中加入 HDFS的URI和NameNode的临时文件夹位置
在文件末尾的configuration标签中添加代码如下:
1 | [root@master hadoop]# vim core-site.xml |
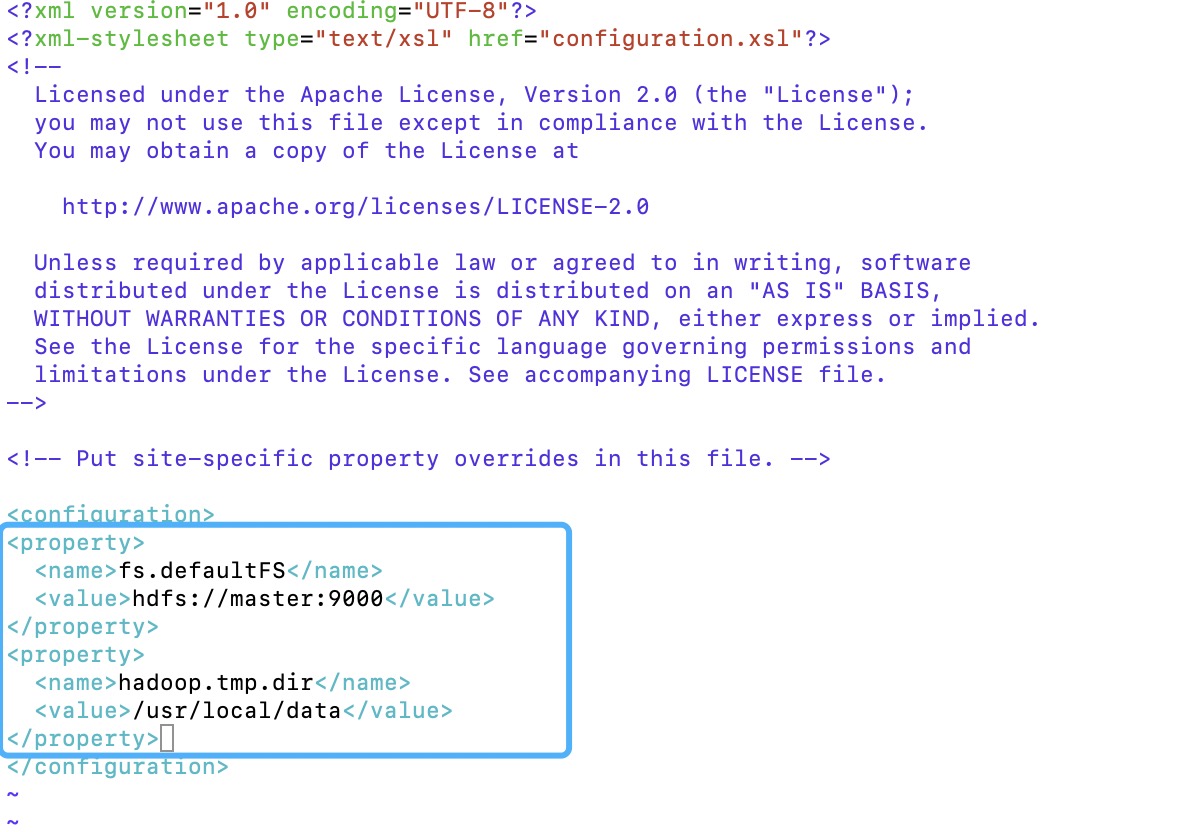
配置文件中的/usr/local/data是用来存储临时文件的,所以该文件夹需要手动创建,另外两个节点也是
1 | [root@master hadoop]# mkdir /usr/local/data |
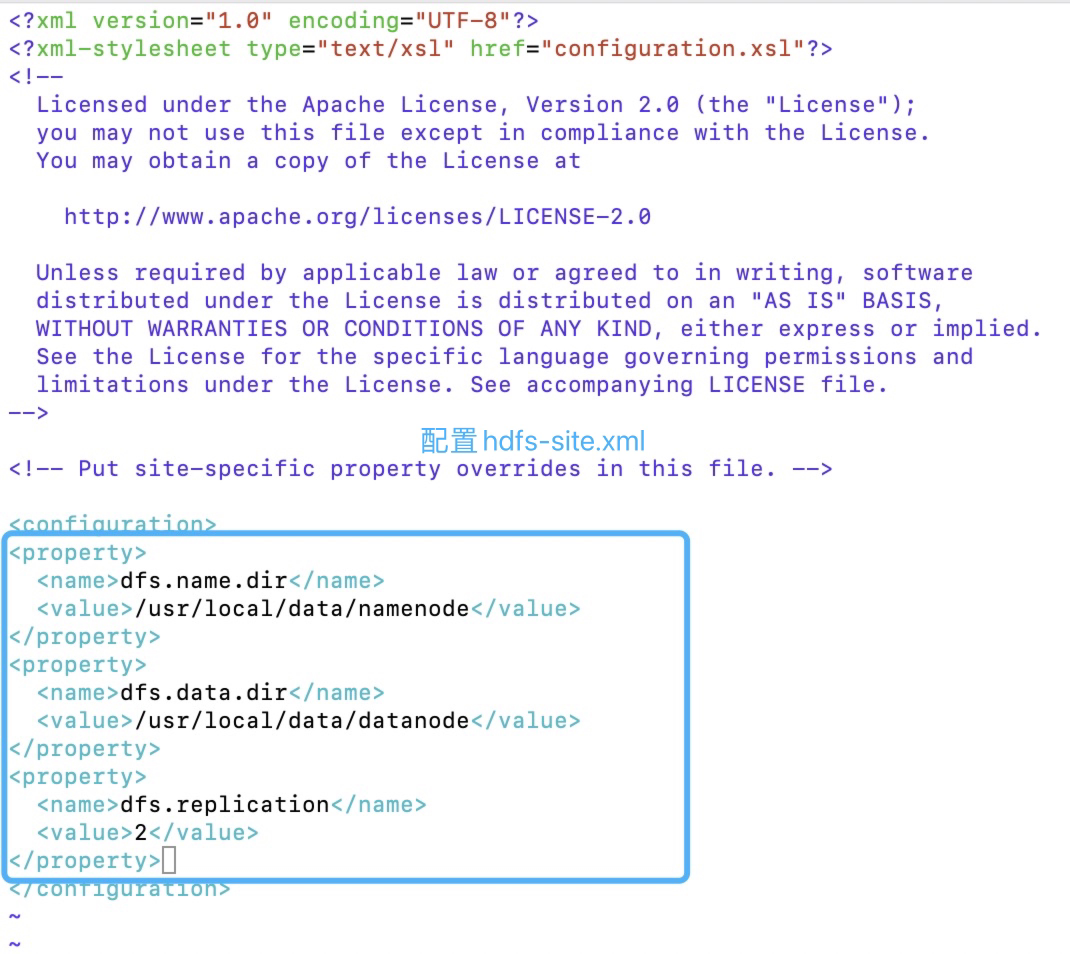
2.hdfs-site.xml
replication指的是副本数量
1 | [root@master hadoop]# vim hdfs-site.xml |
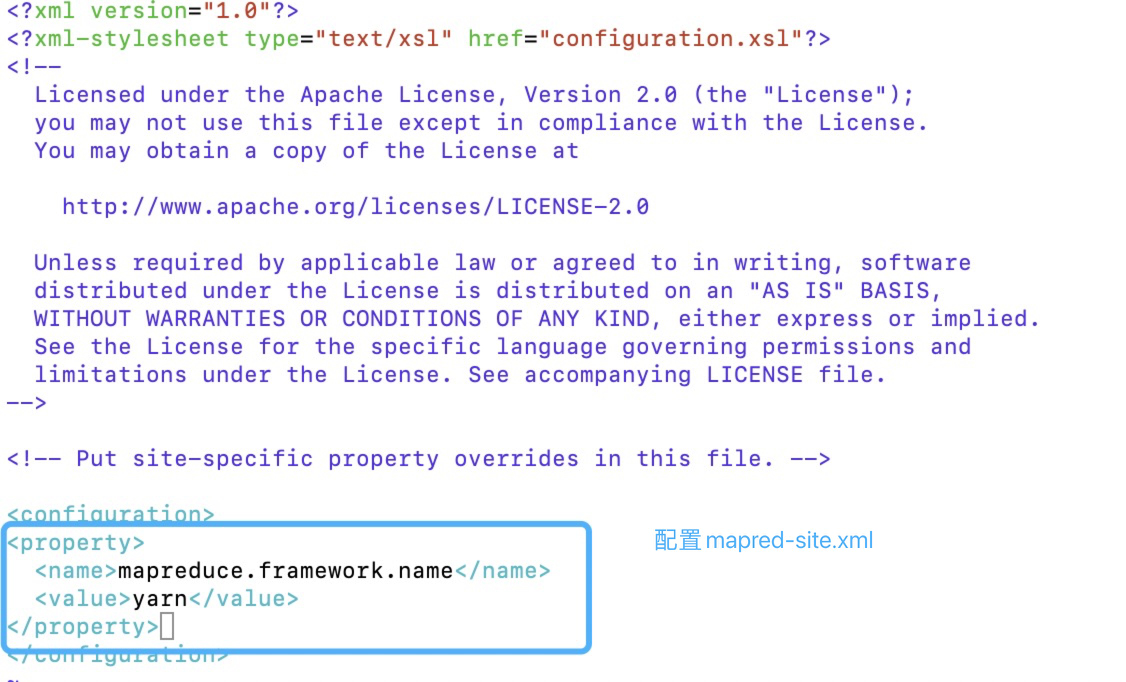
3.mapred-site.xml
- 先修改文件名字
1 | [root@master hadoop]# mv mapred-site.xml.template mapred-site.xml |
1 | <configuration> |
4.yarn-site.xml
1 | [root@master hadoop]# vim yarn-site.xml |
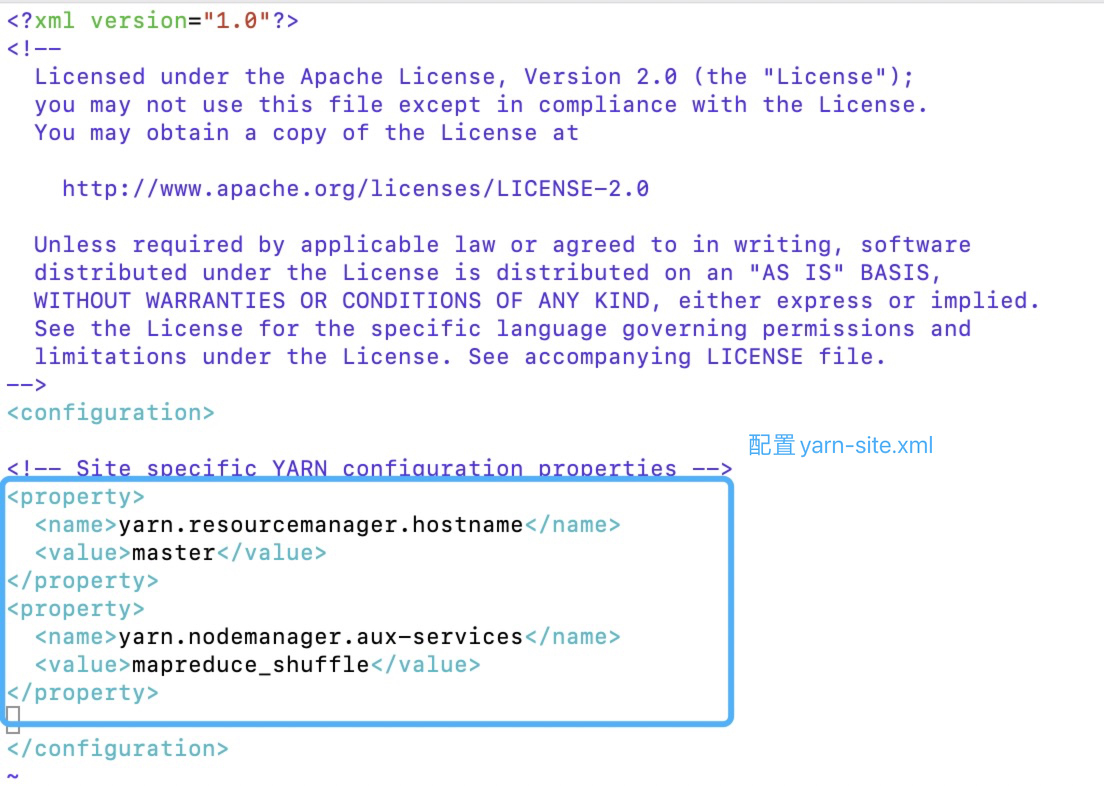
5.slaves
1 | [root@master hadoop]# vim slaves |
6.hadoop-env.sh
1 | [root@master hadoop]# vim hadoop-env.sh |

剩下两个节点重复上述操作
- 在/usr/local/下创建好data目录
- 在/etc/profile配置好环境变量
- scp把配置好的hadoop包传给子节点
1 | [root@master hadoop]# cd /usr/local |
(像配置Java那样profile文件也可以直接scp传给剩下两个子节点,忘记的往前翻)
四、测试Hadoop集群是否成功
- 格式化
- 启动Hadoop
- 验证Hadoop
⚠️只需要在主节点上启动,格式化也只用格式化主节点
(集群是第一次启动,需要格式化NameNode)
1.格式化
在使用Hadoop之前我们需要格式化一些hadoop的基本信息
使用如下命令:
1 | [root@master ~]# hdfs namenode -format |
格式化成功的标志是格式化时输出以下信息: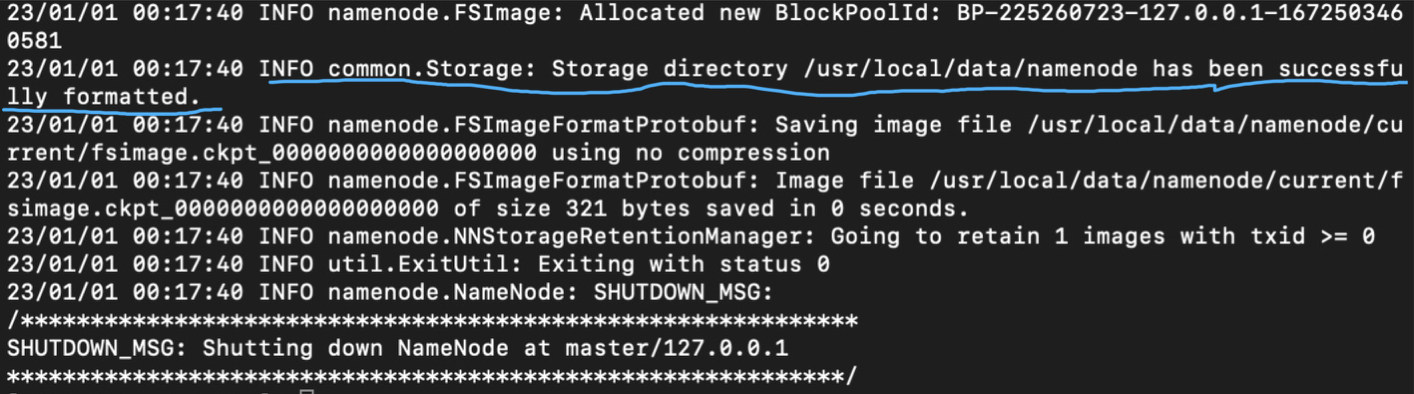
格式化HDFS集群的 NameNode的注意事项
- 集群只有首次搭建后需要对NameNode进行格式化操作
- 如果格式化不成功,或者出现问题的时候,需要重新格式化,格式化之前需要删除所有的进程,一定切记删除所有节点hadoop生成的 data 、logs,jps查看进程,接着删除进程
1 | kill -9 (进程号) |
2.启动Hadoop
在/usr/local/hadoop/hadoop-2.7.7/这个目录噢
[root@master ~]# cd /usr/local/hadoop/hadoop-2.7.7/
- 启动hadoop
[root@master hadoop-2.7.7]# sbin/start-dfs.sh
- 启动yarn
[root@master hadoop-2.7.7]# sbin/start-yarn.sh
- 或者整体启动
[root@master hadoop-2.7.7]# sbin/start-all.sh
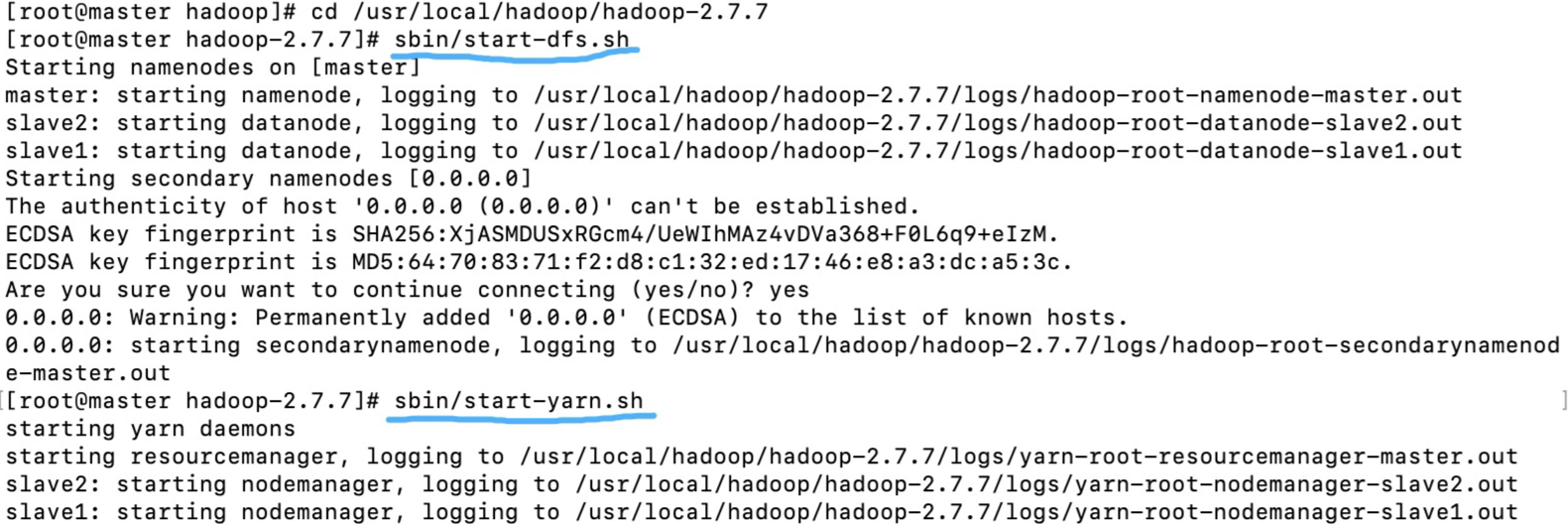
3.验证Hadoop
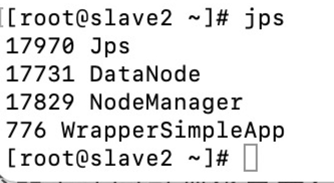
在主节点上输入jps命令查看,以下就对了
在子节点上输入jps命令查看,以下就对了: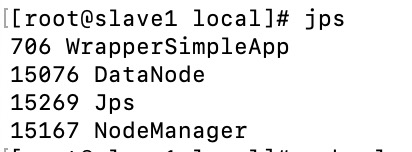
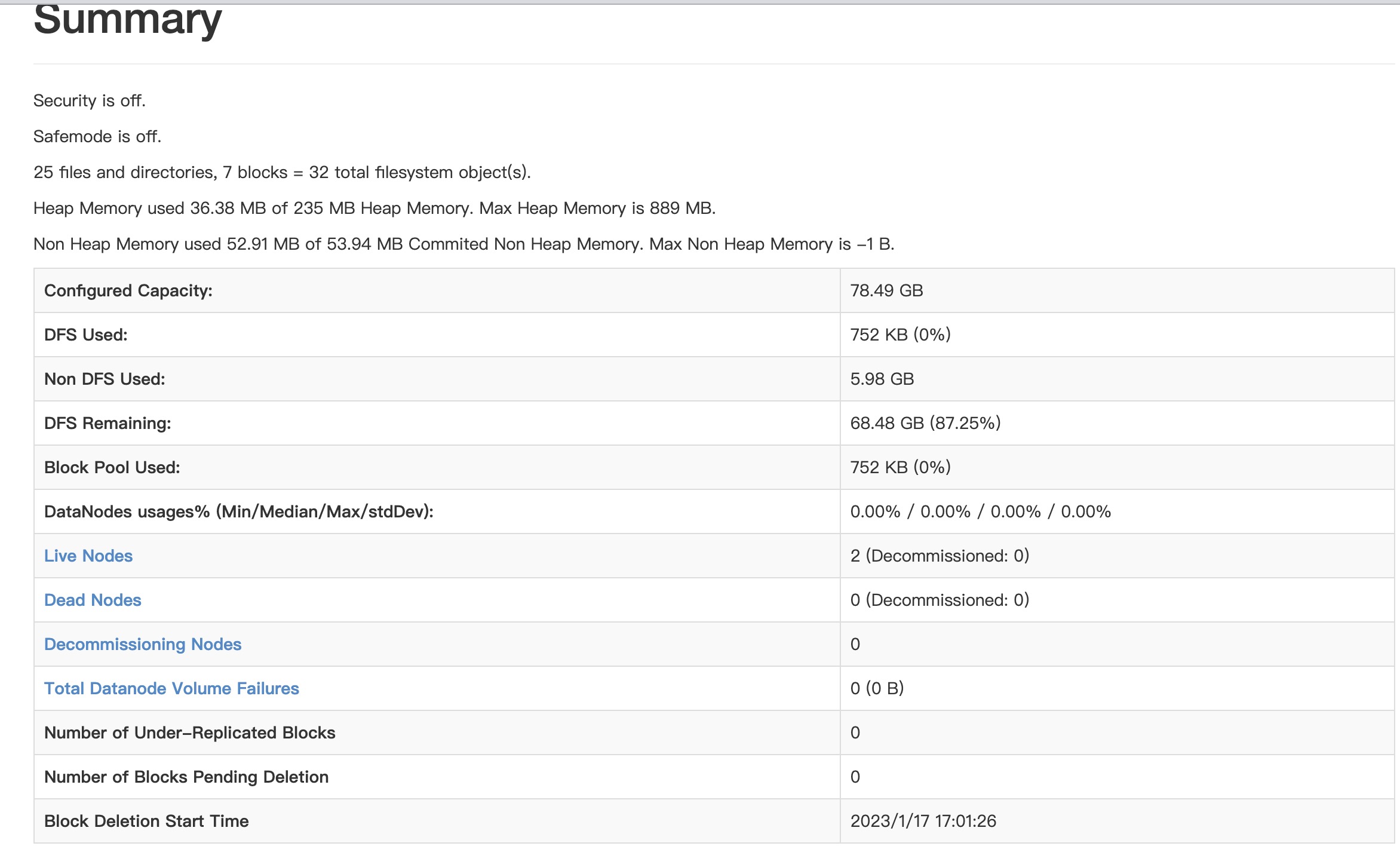
如果你是图形化界面,可以在你虚拟机的图形化界面中打开火狐浏览器输入:http://localhost:50070/
或者在主机上输入http://虚拟机ip地址:50070/ 也可以访问 hadoop的管理页面
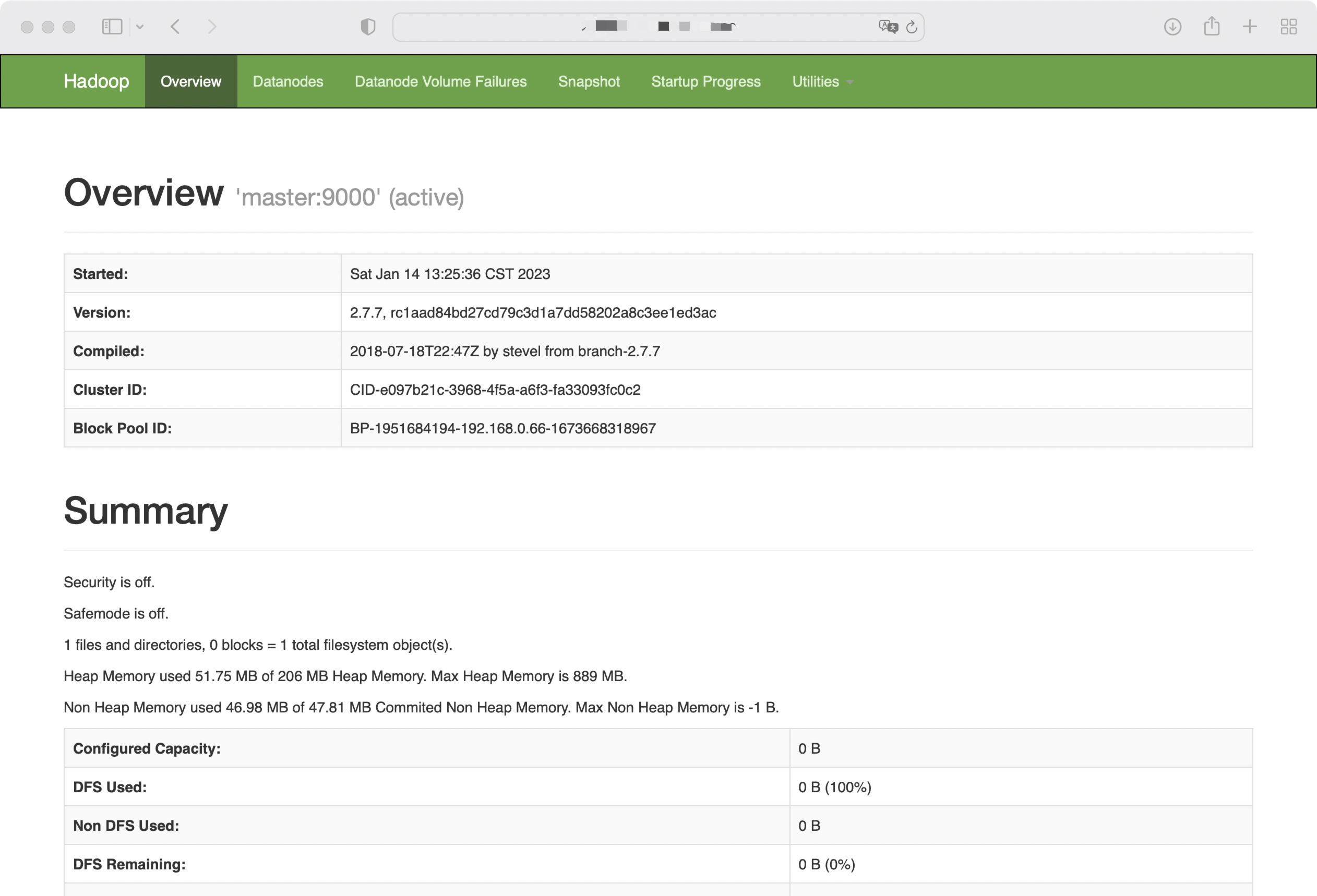
好了到了这一步Hadoop就安装完成了。
五、HDFS系统初体验
- 创建文件夹
和Linux中一样创建文件加的主要命令是mkdir,只不过在前面要加上hadoop fs
- 删除文件夹
hadoop fs -rm (文件夹)
- 查看文件夹
创建好文件加之后,我们可以查看是否创建成功。
命令:hadoop fs -ls /,/代表根目录,这个命令的意思就是查看根目录下所有的文件和文件夹hadoop fs -ls /
上传文件至HDFS
在本地编写文件,然后上传到HDFS中。
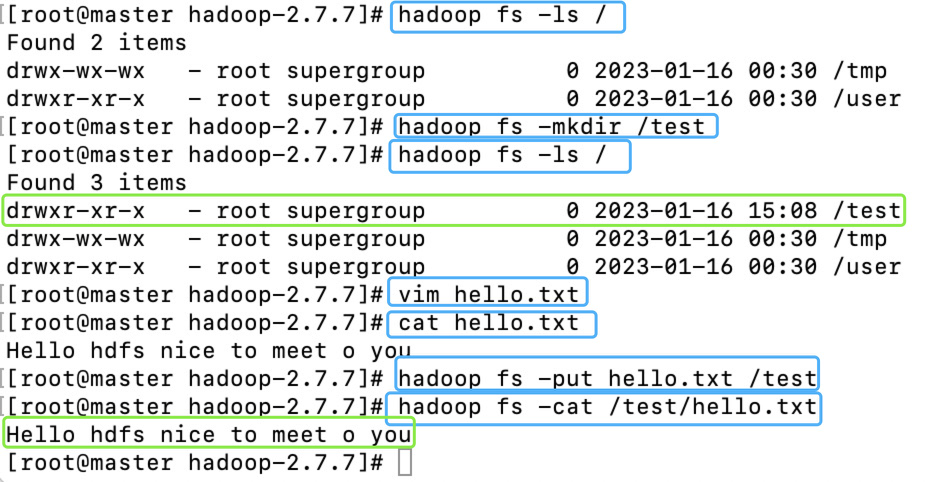
1.创建文件,并添加数据
1 | touch hello.txt |
2.将文件上传至HDFS
使用put命令即可将指定文件上传至HDFS的指定文件夹中,在本文中就是将hello.txt上传至HDFS的/test文件夹。
1 | hadoop fs -mkdir /test |
⚠️如果文件上传报错,回头检查一下三台机子是否在一个局域网里,只能用内网IP(如果安全组设置了对方IP也可以公网IP),是否在一个网段
3.查看文件
与Linux中查看文件类似,使用cat命令即可查看指定文件的内容。
hadoop fs -cat /test/hello.txt
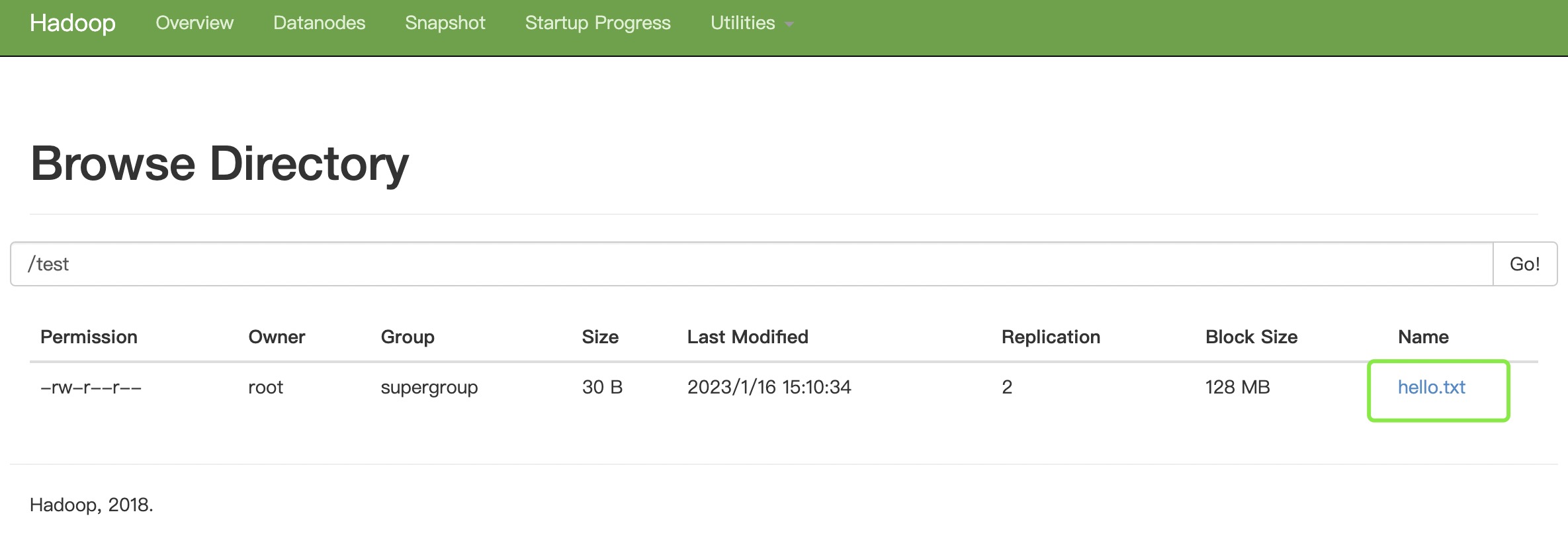
到这里🍃Hadoop完全分布式就完成啦,配置文件部分一定要仔细噢~祝你成功!
参考资料
https://blog.csdn.net/pig2guang/article/details/85313410
https://blog.csdn.net/yandao/article/details/124240656
—— 本文完 · 感谢读到这里的你 🐾 ——